

什么是上下文窗口
上下文窗口是 AI 模型在一次生成回答时,能够同时读取、保留并参与计算的最大文本范围。这个范围按 Token 计算,不按页数、字数或轮次数计算。
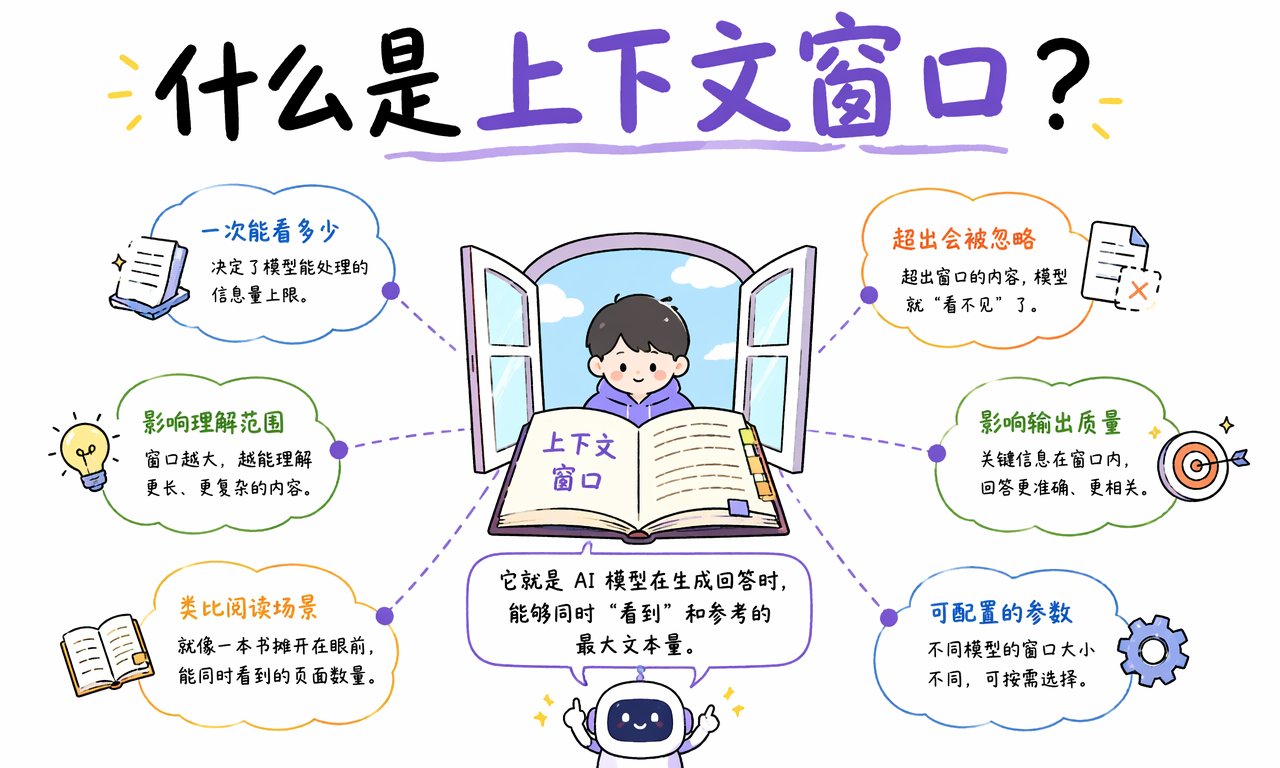
如果把模型想象成一个正在阅读的人,上下文窗口就是它一次能摊开在眼前、随时来回扫视的页面总量。窗口里的系统提示词、聊天历史、文档片段和当前问题,会一起被送进模型的计算核心;窗口之外的内容,对模型来说等于当前不存在。
更具体地说,上下文窗口解决的是模型“短期工作记忆”有限的问题。它决定模型此刻能基于哪些材料继续推理、总结、翻译、写代码或回答问题。结论很直接:上下文窗口越大,模型一次能处理的信息越多,但成本、延迟和稳定性挑战也会一起上升。
为什么上下文窗口会影响回答质量
上下文窗口会直接影响回答质量,因为模型只能基于窗口内仍然可见的 Token 继续推理。只要关键事实、规则或定义被挤出窗口,后续回答就可能建立在残缺信息上。
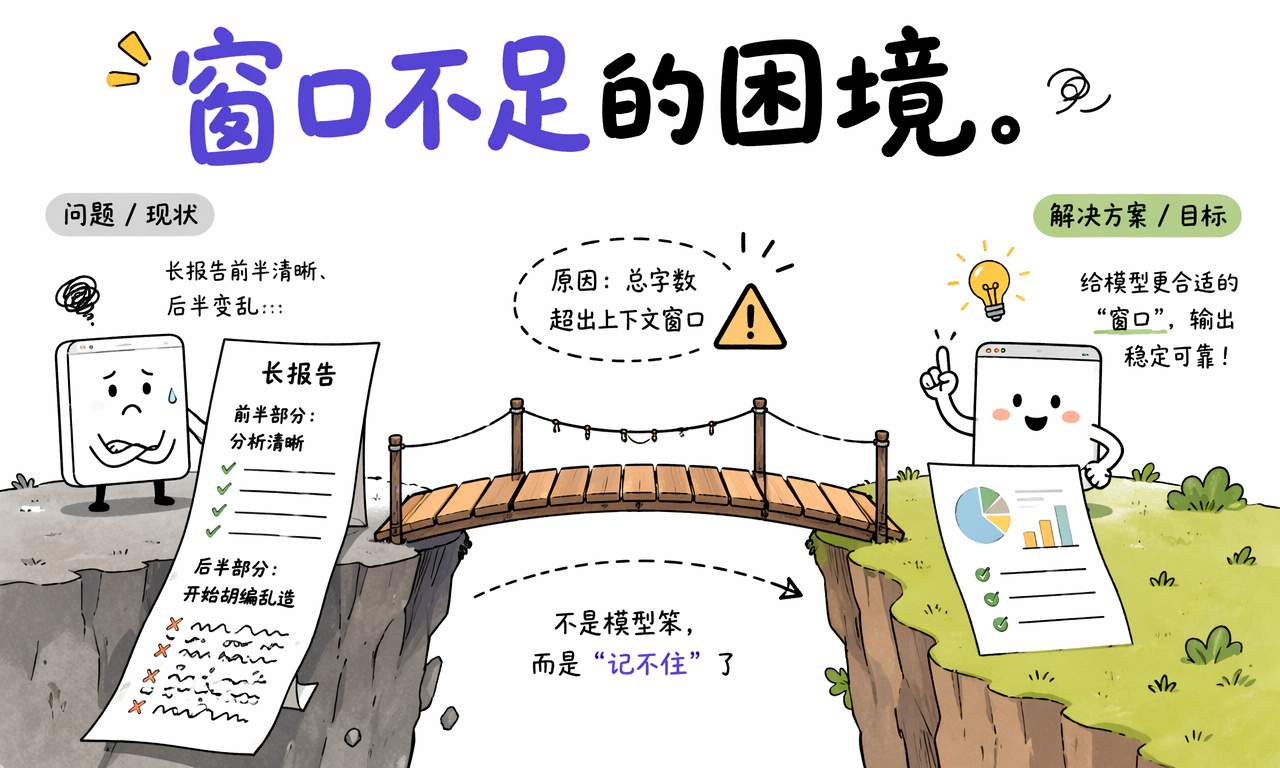
一个常见场景是总结长报告。前半段分析很准确,到了结尾却开始张冠李戴,通常不是模型突然“变笨”,而是报告总长度超过了窗口上限。系统为了容纳新输入,会截断更早的内容,模型于是失去前文事实基础。
这种影响主要体现在三类任务里:
- 长文档总结:早期章节容易被截断,结论可能与前文不一致。
- 长对话助手:模型会忘记之前确认过的要求、术语和约束。
- 代码协作:前面定义的函数、接口和报错背景被挤掉后,模型容易虚构实现细节。
因此,上下文窗口影响的不只是“能不能塞进去”,还影响“模型还能不能持续保持同一套事实和约束”。
上下文窗口是怎么工作的
上下文窗口本质上是一段会滑动的 Token 缓冲区。模型不会真的长期记住你这个人,它只会在当前请求里读取一个有限范围内的信息,然后基于这批信息预测下一个 Token。
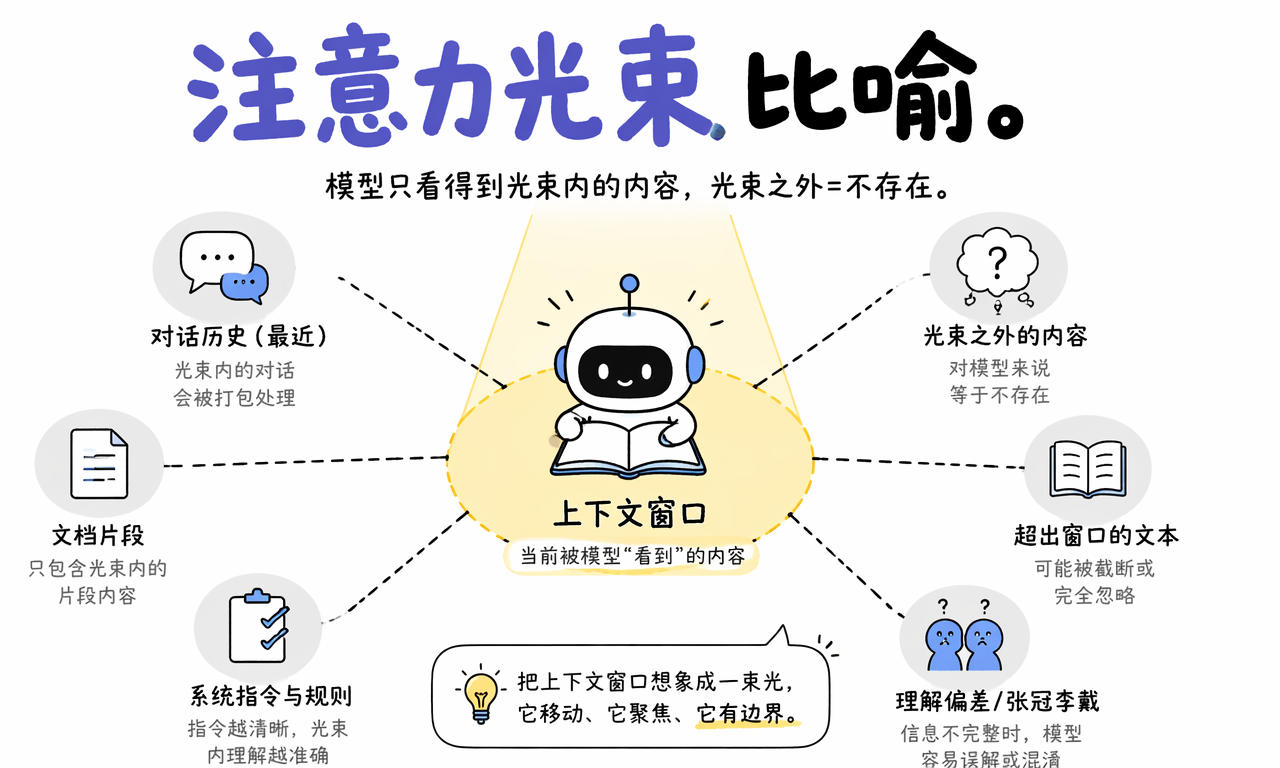
可以把它理解成一束会移动的注意力光束,工作流程通常是这样的:
- 输入被切成 Token:系统提示词、历史消息、文档内容和你的当前问题都会先被 tokenization。
- Token 被打包进窗口:所有内容按顺序拼接,直到接近该模型的上下文上限。
- 超出的内容被截断或压缩:最早的消息、低优先级片段或旧摘要会先被丢弃。
- 模型在当前窗口内计算:它只对窗口内还存在的 Token 做注意力计算和下一个 Token 预测。
这也是为什么很多产品明明看起来是“连续聊天”,底层却仍然是一次次重新打包上下文再发给模型。模型没有天然的人格记忆,只有每次请求被重新构造出的当前工作记忆。
Token 和上下文容量是什么关系
上下文窗口的容量单位是 Token。你看到的 4K、8K、128K 或 1M 上下文,本质上是在说模型一次最多能处理多少 Token。
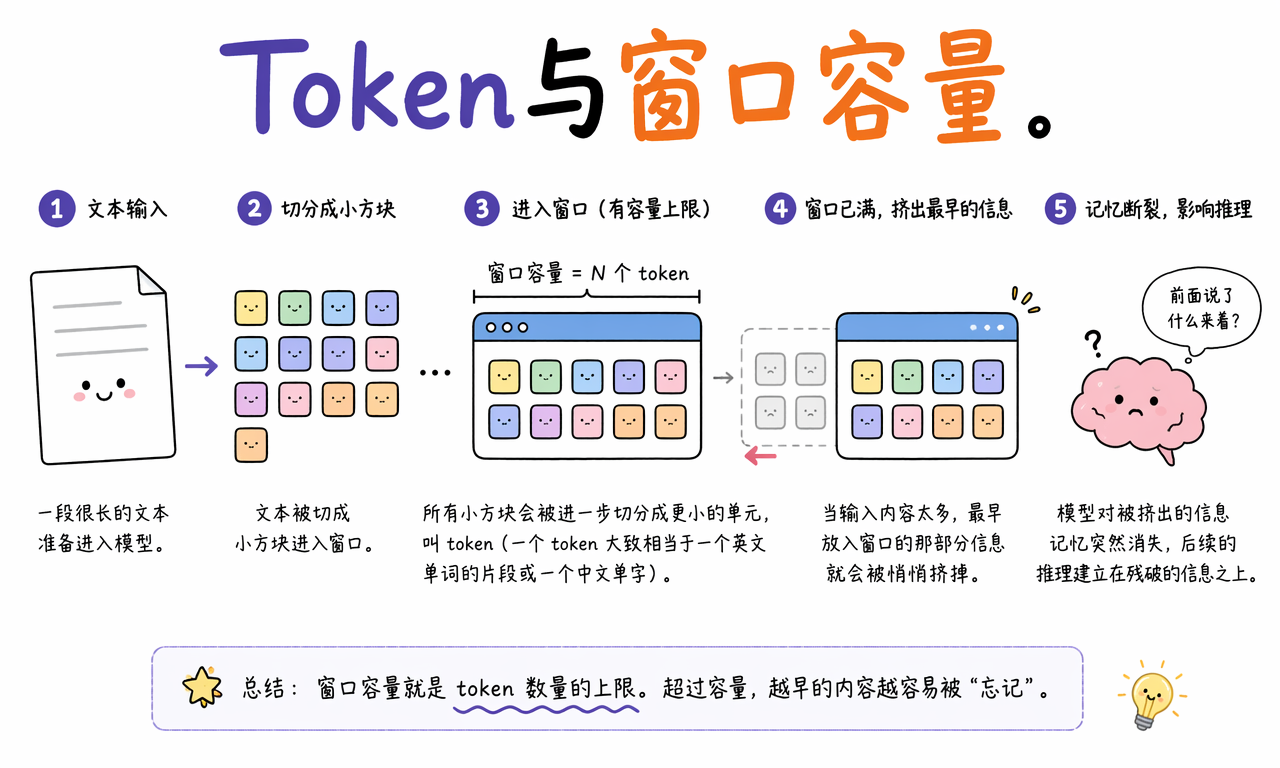
一个 Token 大致可以理解为英文单词片段、中文单字或更小的文本单位,但它不是固定等于一个字或一个词。同样一段中文、英文、代码、表格或 URL,占用的 Token 数差异可能非常大。
下面这张表适合用来快速理解常见窗口规格:
| 标称窗口 | 大致含义 | 适合任务 | 常见限制 |
|---|---|---|---|
| 4K | 约 4096 Token | 短问答、简单摘要、轻量代码解释 | 很容易被历史对话占满 |
| 8K 到 32K | 几千到几万 Token | 中等长度文档、常规编程协作 | 长材料仍需分段 |
| 128K | 十万级 Token | 大型报告、长会议纪要、多文件代码分析 | 成本和延迟明显增加 |
| 1M 左右 | 百万级 Token | 超长资料通读、整库分析、长链工作流 | 中部检索精度和推理稳定性仍可能下降 |
因此,窗口数字越大不代表“万事无忧”。它只说明模型在理论上能看见更多内容,不保证对所有位置的内容都同样敏感。
为什么长上下文会出现“迷失在中间”
长上下文并不等于均匀记忆。大量研究和实际测试都表明,窗口越长,模型越可能对中间位置的信息检索不稳定,这类现象通常被称为“迷失在中间”。
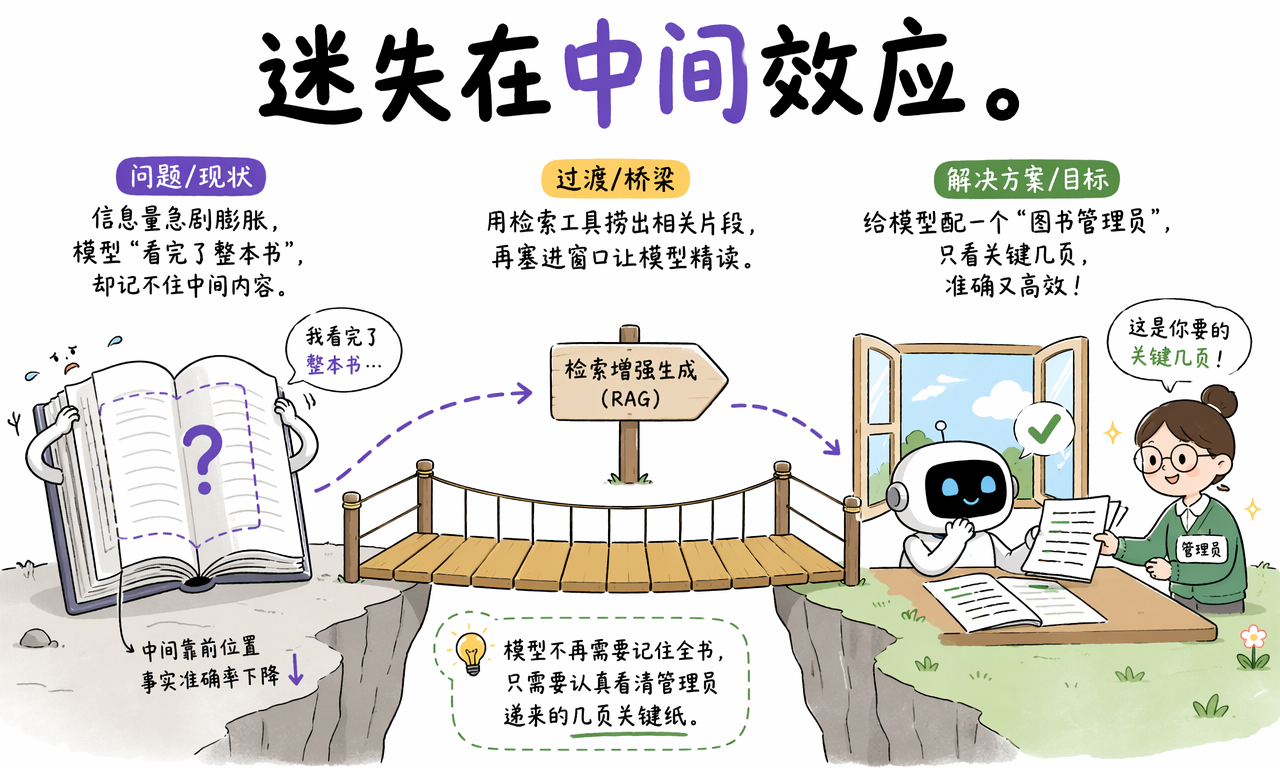
直观理解就是:模型嘴上可以说“我读完了整份材料”,但真正需要从很长的上下文中精准抽取某个中部事实时,命中率会下降。对用户来说,表现往往是:
- 明明文档里写过,模型却说“没有看到相关信息”。
- 结尾部分能复述,开头部分也能提到,但中间章节细节被漏掉。
- 多个相似人物、接口或概念在长上下文里被混淆。
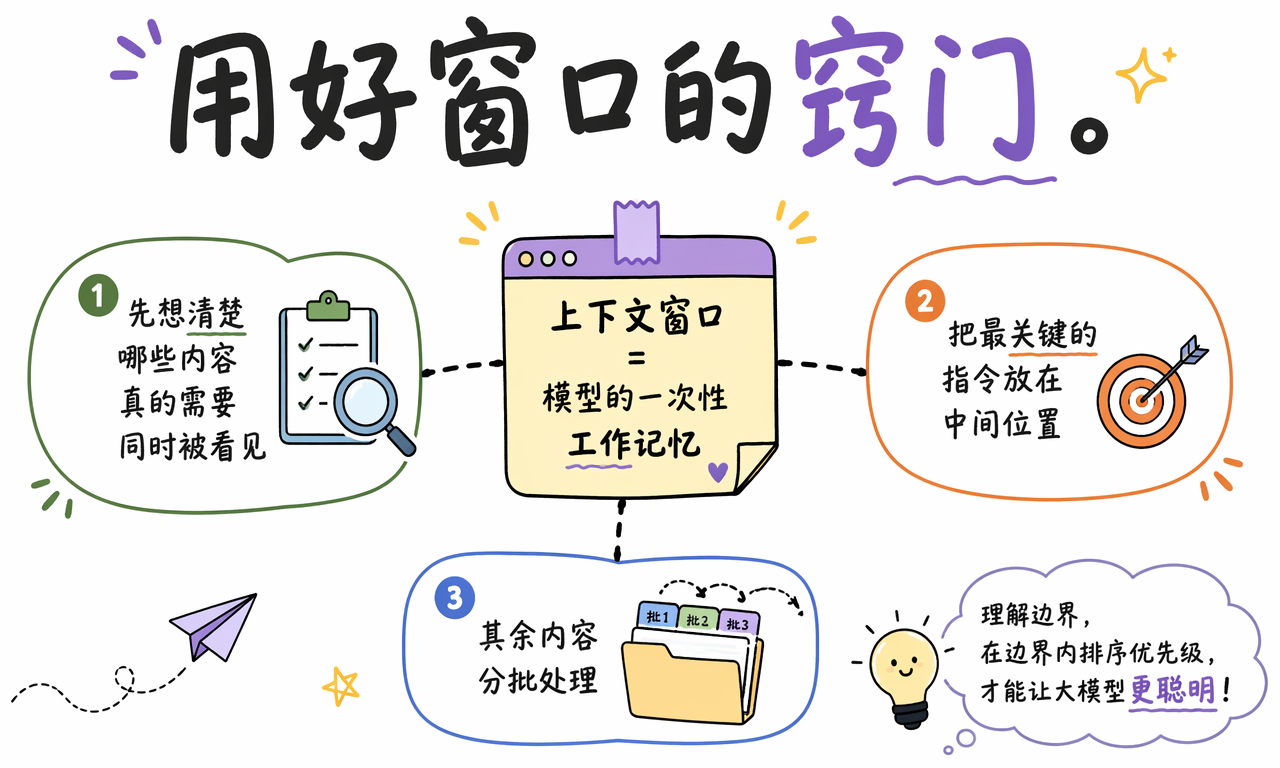
这也是一个需要纠正的常见误解:关键指令不应该只赌在中间位置。更稳妥的做法通常是把核心任务放在开头,并在接近回答位置时用更短的形式重复一次,让模型在“入口”和“输出前”都能看到它。
一句话总结:长窗口提升了可容纳信息量,但没有消灭位置偏差。
为什么大窗口会更贵、更慢
大窗口会更贵、更慢,因为模型需要在一次推理中处理更多 Token 之间的关系。可参与计算的 Token 越多,内存占用、显存带宽压力和整体延迟通常都会显著上升。
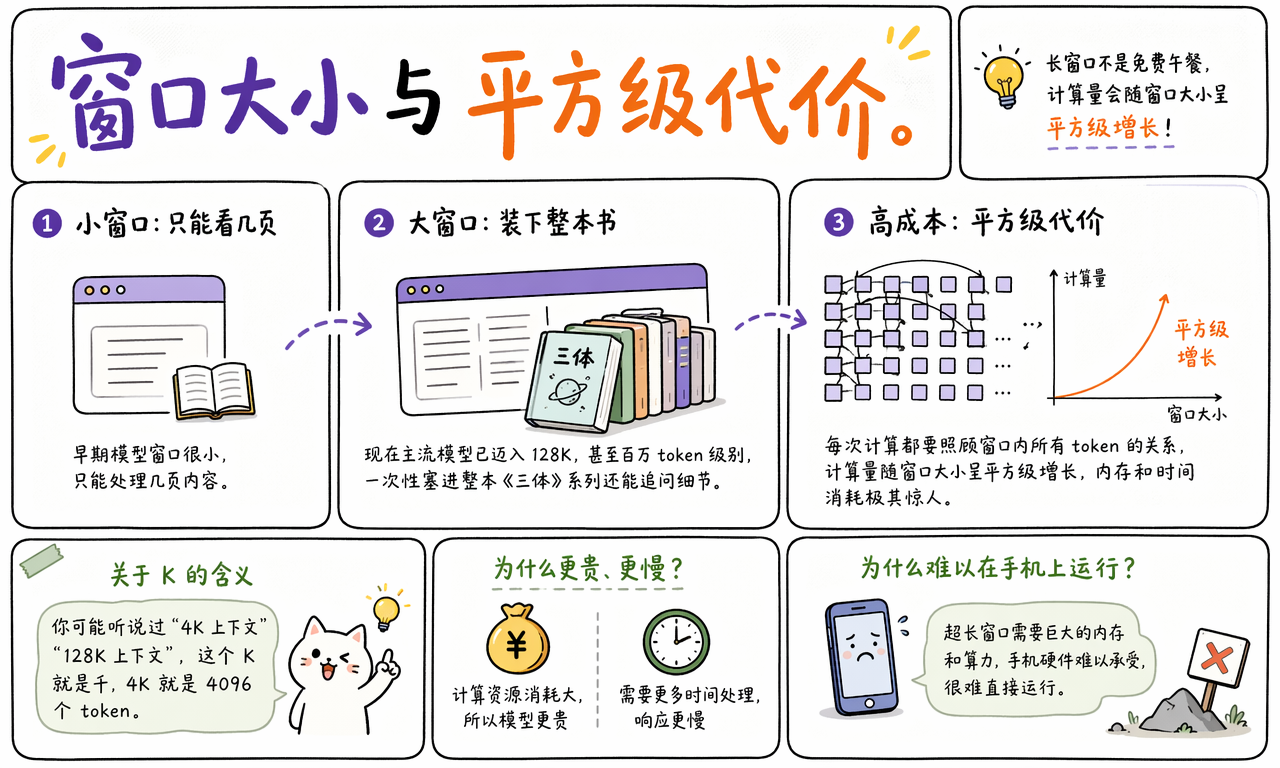
从产品侧看,这会带来三个直接后果:
- API 成本增加:输入 Token 越多,账单通常越高。
- 首字延迟增加:模型需要先读完整个上下文,再开始生成。
- 设备门槛更高:超长上下文模型更依赖高内存和高带宽硬件。
所以,长窗口是能力扩展,也是资源竞争。为什么很多模型厂商把 128K、256K 或百万 Token 当成卖点,本质上是在比拼谁能在更大的工作记忆里维持可接受的成本和准确率。
长上下文和 RAG 应该怎么选
长上下文和 RAG 不是互斥关系,而是两种不同的上下文管理策略。长上下文强调“一次塞进更多内容”,RAG 强调“先检索出相关内容,再喂给模型”。
可以用这张表快速比较:
| 方案 | 核心思路 | 优点 | 局限 | 更适合的场景 |
|---|---|---|---|---|
| 直接长上下文 | 把大量原始材料整体放进窗口 | 上手简单,保留原文细节多 | 成本高,中部命中率可能下降 | 单份长文精读、少量文件通读 |
| RAG | 先检索相关片段,再送入窗口 | 更省 Token,聚焦度更高 | 依赖检索质量,可能漏召回 | 知识库问答、企业搜索、多文档问答 |
| 长上下文 + RAG | 先检索,再给模型较大的阅读空间 | 兼顾覆盖率和准确率 | 架构更复杂,需要调参与监控 | 复杂 Agent、代码库助手、生产级问答系统 |
实际工程里,常见做法不是在两者之间二选一,而是让 RAG 先做召回,再让较大的上下文窗口做精读和整合。这样可以把模型的注意力用在真正相关的几页纸上,而不是整座图书馆。
上下文窗口为什么会影响编程和持续写作
上下文窗口会影响编程和持续写作,因为这两类任务都依赖跨轮次的一致性。模型需要持续记住命名约定、目录结构、已确认结论、错误堆栈和输出格式。
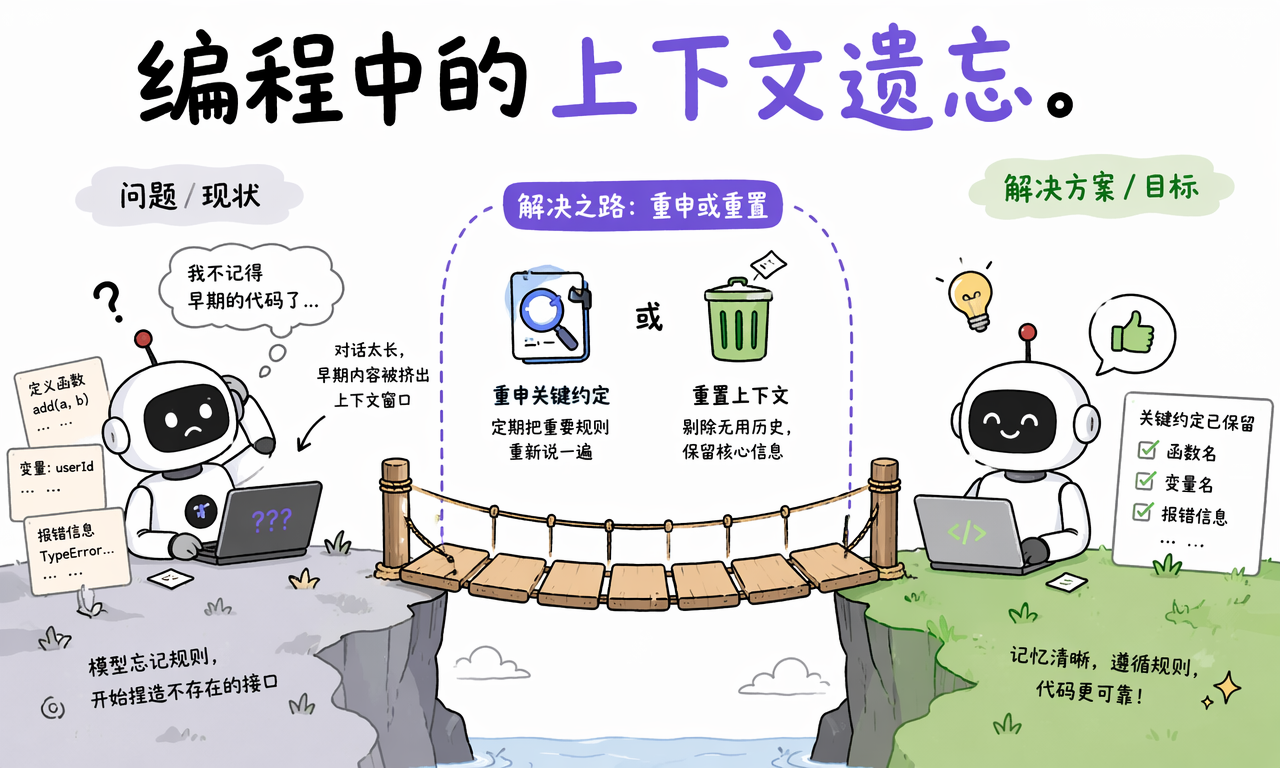
当对话越来越长时,最早约定好的内容会先被挤出窗口,结果通常表现为:
- 代码助手开始调用不存在的函数或文件。
- 写作助手重新定义前面已经定过的术语。
- 模型忘记之前确认过的禁止事项,重新走回错误路径。
这也是为什么很多经验用户会定期做“上下文整理”:
- 用一段摘要重述当前目标、约束和结论。
- 删除已经无关的历史对话和重复解释。
- 只提供当前修改真正相关的文件片段。
结论是,持续性任务不是单纯依赖更大窗口,而是依赖更好的上下文管理。
如何判断自己已经碰到窗口边界
多数聊天产品不会给你一个显眼的“窗口已用掉 83%”提示,所以用户通常只能通过行为迹象判断上下文是否快满了。
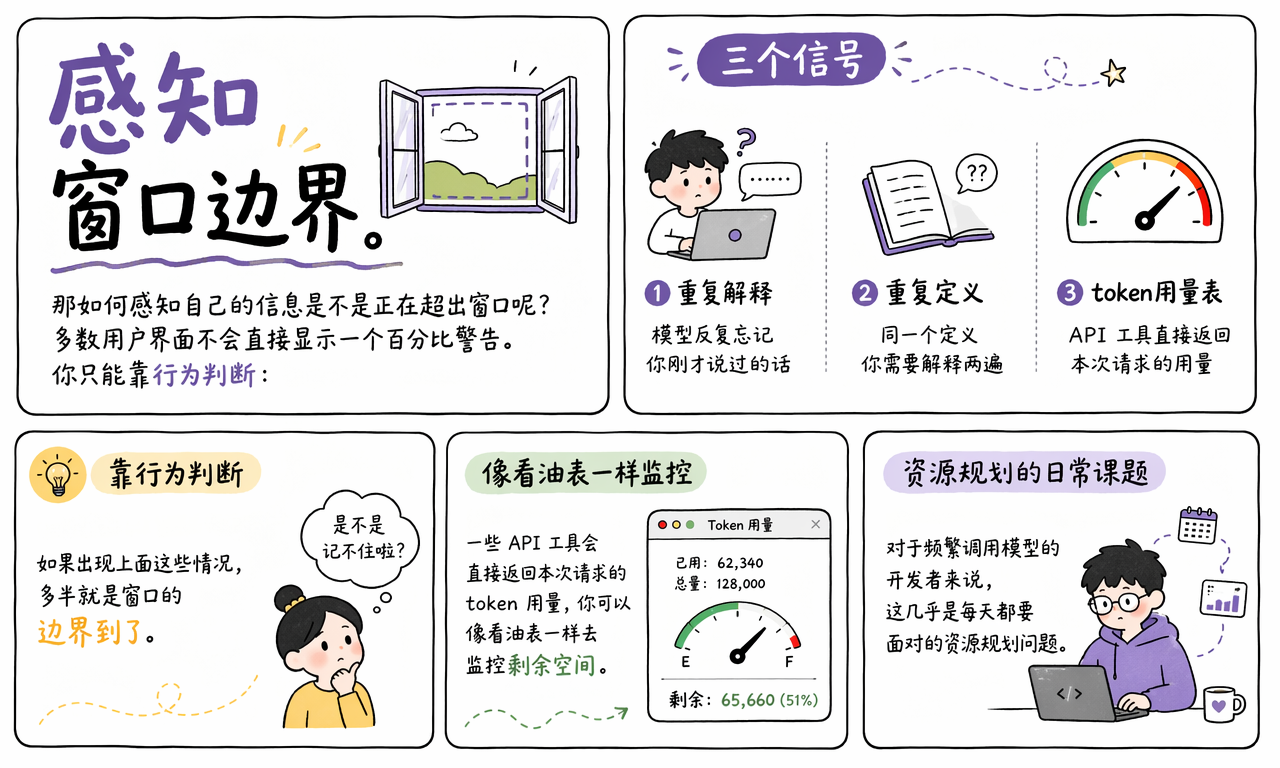
下面这些现象通常是明确信号:
- 模型反复忘记你刚刚设定的规则。
- 同一个定义需要解释两遍甚至三遍。
- 长文总结后半段开始出现编造、混淆或跳步。
- 编程任务里开始频繁生成不存在的接口名。
如果你在用 API,还可以直接看每次请求返回的 Token 用量、上下文占用和输出长度。对开发者来说,这和监控 CPU、内存、响应时间一样,属于必须长期盯住的资源指标。
上下文窗口有哪些隐藏限制和常见误区
上下文窗口很容易被神化,但它有明确边界。下面这些限制在实际使用里最常见:
| 误区或限制 | 更准确的理解 | 实际建议 |
|---|---|---|
| 窗口越大,模型越聪明 | 大窗口只扩大可见范围,不自动提升推理质量 | 先控制输入质量,再追求更长窗口 |
| 128K 等于能稳定读完超长文档 | 能塞进去不等于能稳定检索每个细节 | 对长文仍要分段、摘要或加检索 |
| 模型会长期记住所有历史 | 模型只直接看到当前请求里仍保留的上下文 | 重要规则要定期重述 |
| 只要窗口够长,就不需要 RAG | 超长上下文仍可能贵、慢、漏中间信息 | 多文档系统优先考虑检索增强 |
| 关键指令放任意位置都行 | 位置信号会影响命中率 | 核心要求放开头,并在输出前附近重复 |
一句话总结:上下文窗口是工作记忆,不是永久记忆,也不是无限注意力。
记忆压缩和外挂记忆会取代上下文窗口吗
不会完全取代,但会扩展有效记忆范围。越来越多的新架构会把较远的历史压缩成摘要、状态或向量表示,再通过检索机制按需调回当前窗口。
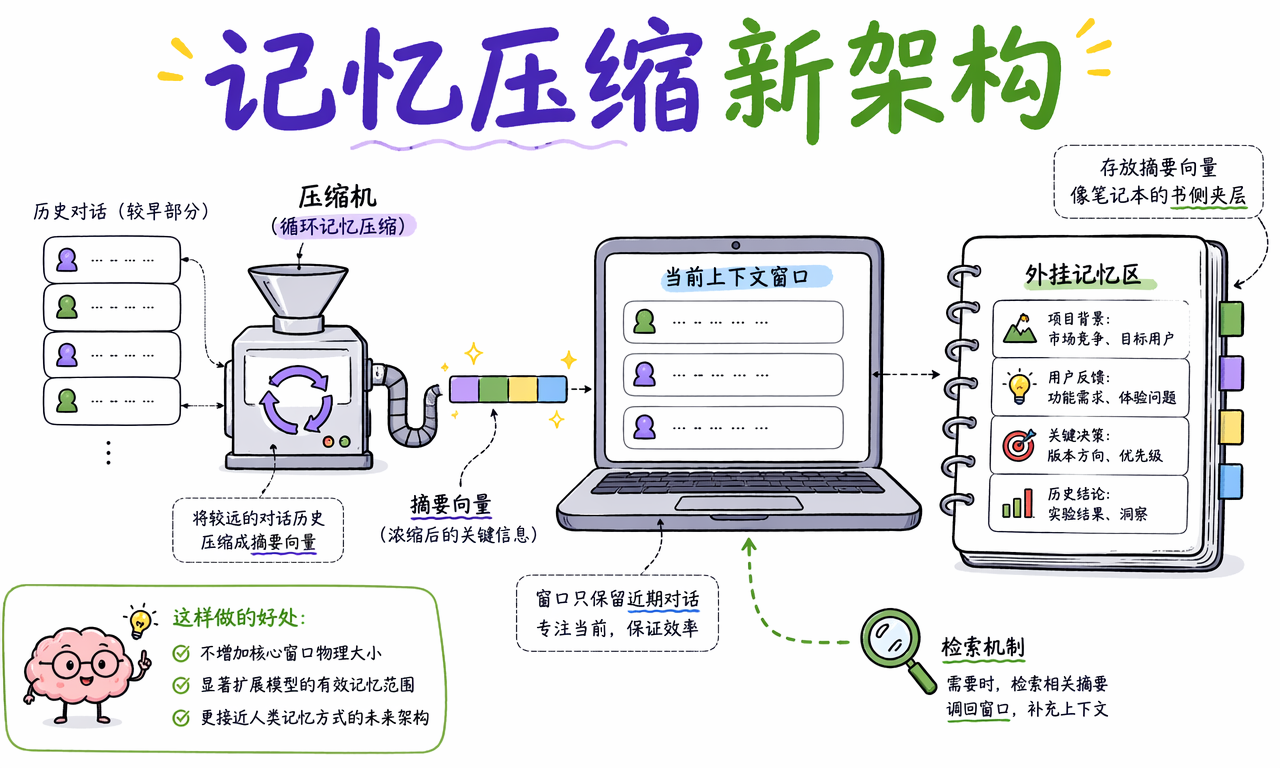
这类思路通常包括:
- 对旧对话做摘要压缩,只保留关键状态。
- 把远期信息存到向量库或外部记忆层。
- 当前任务需要时,再把相关摘要或片段检索回窗口。
你可以把它理解成“模型本体的工作记忆 + 外挂笔记本”。翻过去的页面不是完全丢掉,而是先提炼成索引,需要时再翻回来。这会是未来 Agent、长对话助手和复杂工作流系统的重要方向。
常见问题
上下文窗口和 Token 有什么关系?
上下文窗口是按 Token 计量的容量上限。Token 是模型处理文本和多模态信息的基本计算单位,窗口则是这些 Token 一次最多能放进去多少。
4K、8K、128K 上下文是什么意思?
它表示模型一次请求中最多可处理的大致 Token 数量。4K 约等于 4096 Token,128K 约等于 12.8 万 Token,但不等于同样数量的汉字或单词。
上下文窗口越大越好吗?
不一定。更大的窗口通常意味着更高成本、更长延迟,以及在超长材料里更明显的位置偏差。是否更好,要看你的任务是否真的需要一次处理那么多信息。
为什么 AI 聊久了会变得不靠谱?
因为早期对话内容可能已经被挤出窗口。模型失去前面的事实、规则或约定后,就会开始依赖不完整的信息继续生成。
长上下文可以替代 RAG 吗?
通常不能完全替代。长上下文适合直接精读长材料,RAG 适合从大量资料里先找出相关片段。生产环境里,两者经常结合使用。
总结
上下文窗口就是模型的一次性工作记忆。它决定 AI 在当前这一轮里到底能同时看见哪些内容,能否保持长对话一致性,能否稳定总结长文档,也决定了你要付出多少成本和等待多久。
真正会用大模型的人,不会只盯着“窗口有多大”,而会主动管理“什么信息值得留在窗口里”。把核心目标放在开头,把关键限制在回答前再次强调,把无关历史及时删掉,把超长资料交给分段摘要或 RAG 处理。这样即使窗口不是无限大,模型也更容易给出稳定、聪明且可用的回答。