
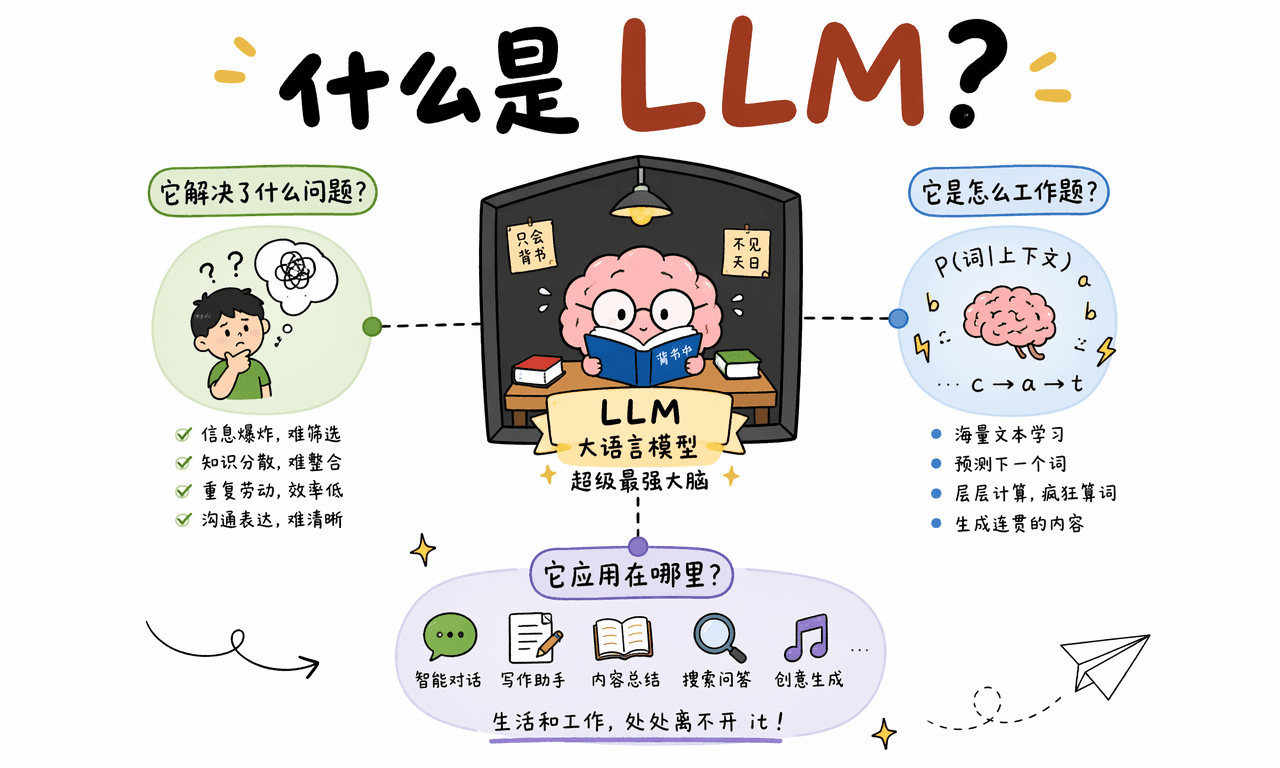
LLM 到底是什么
什么是 LLM,也就是大语言模型?一句话说,它就像一个被关在小黑屋里、只会背书和算词的“超级最强大脑”。
它读过海量文本,见过无数句子的开头、转折、结尾和表达习惯。当你给它一句话,它不会像人一样真正坐在那里沉思人生,而是在脑子里疯狂计算:在当前上下文后面,最可能出现的下一个词是什么?
这篇文章会从大语言模型到底解决了什么问题开始,一步步讲清楚它是怎么把人类文字拆成 token、怎么预测下一个词、怎么一个字一个字生成回答,最后再看看它已经在哪些日常场景里变成了基础设施。
电脑以前为什么听不懂人话
以前咱们让电脑干活,最大的痛点是:它像个死脑筋的算盘。
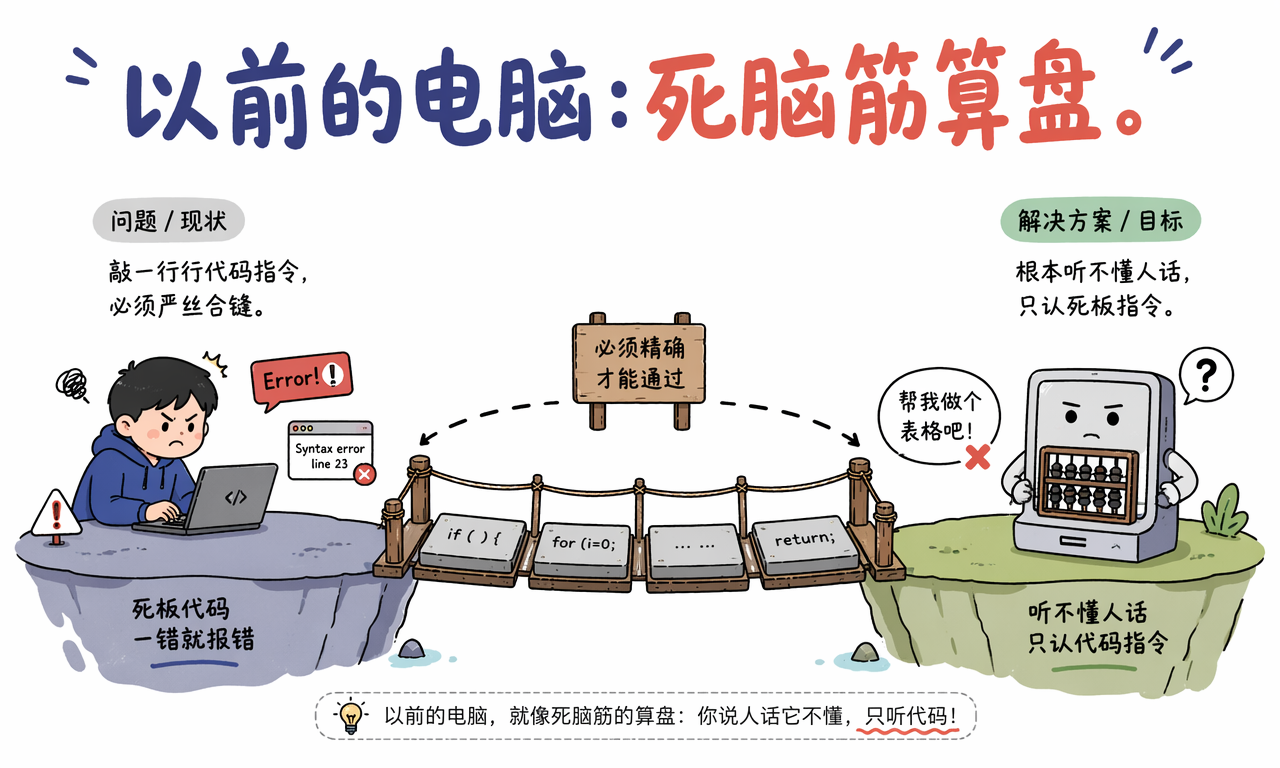
你必须敲下一行行严丝合缝的代码指令,函数名、括号、引号、分号都不能错。稍微多一个空格、少一个标点、拼错一个字母,它就可能直接报错。
这不是电脑故意摆烂,而是传统软件的交互方式本来就很死板:人要先把自己的目标翻译成机器能理解的精确指令,机器再照着执行。
问题是,大多数人并不想学编程语言。人更自然的表达方式是:“帮我总结一下这篇文章”“把这封邮件写得礼貌一点”“这段代码为什么报错”“我想做一个周报模板”。
LLM 要解决的核心问题,就是把机器从“只能听懂死板代码”的状态,推进到“能理解自然语言意图”的状态。
大语言模型的三件大事
为了让机器能像人一样沟通和流转,LLM 的训练目标可以简单拆成三件事:海量吞咽人类知识、精准预测下一个词、对齐喜好乖乖听话。
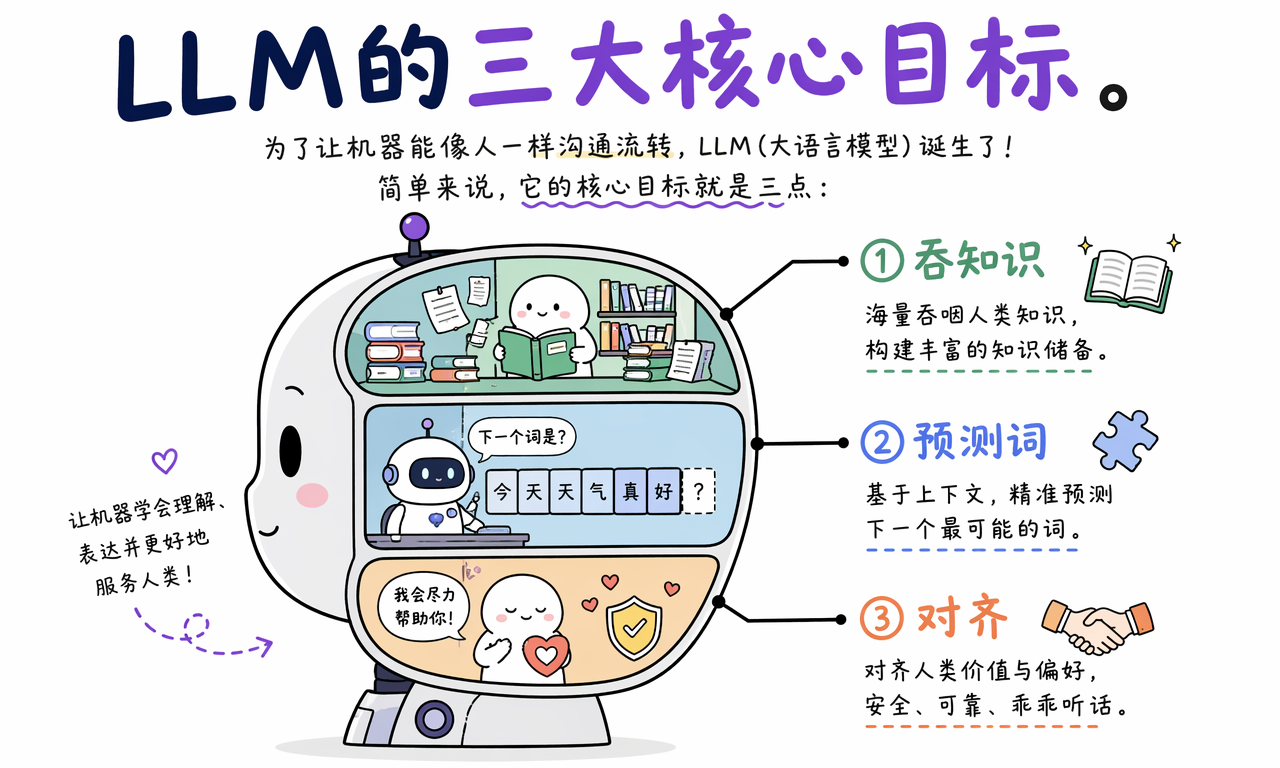
第一件事,是吞下足够多的文本。模型需要见过大量文章、书籍、网页、代码和对话,才能学到语言的统计规律、知识关联和表达套路。
第二件事,是学会预测下一个 token。这里的 token 可以粗略理解成“文字碎片”:有时是一个汉字,有时是一个词,有时是一个标点,也可能是一段英文单词的一部分。模型真正做的事,就是根据上文计算每个候选 token 的概率。
第三件事,是学会按人类喜欢的方式回答。光会接龙还不够,它还要尽量有用、诚实、礼貌、安全,不要动不动胡编乱造,更不能教人干坏事。
第一步:预训练,关进小黑屋死记硬背
大语言模型干活的第一步,叫预训练。用更接地气的话说,就是死记硬背。
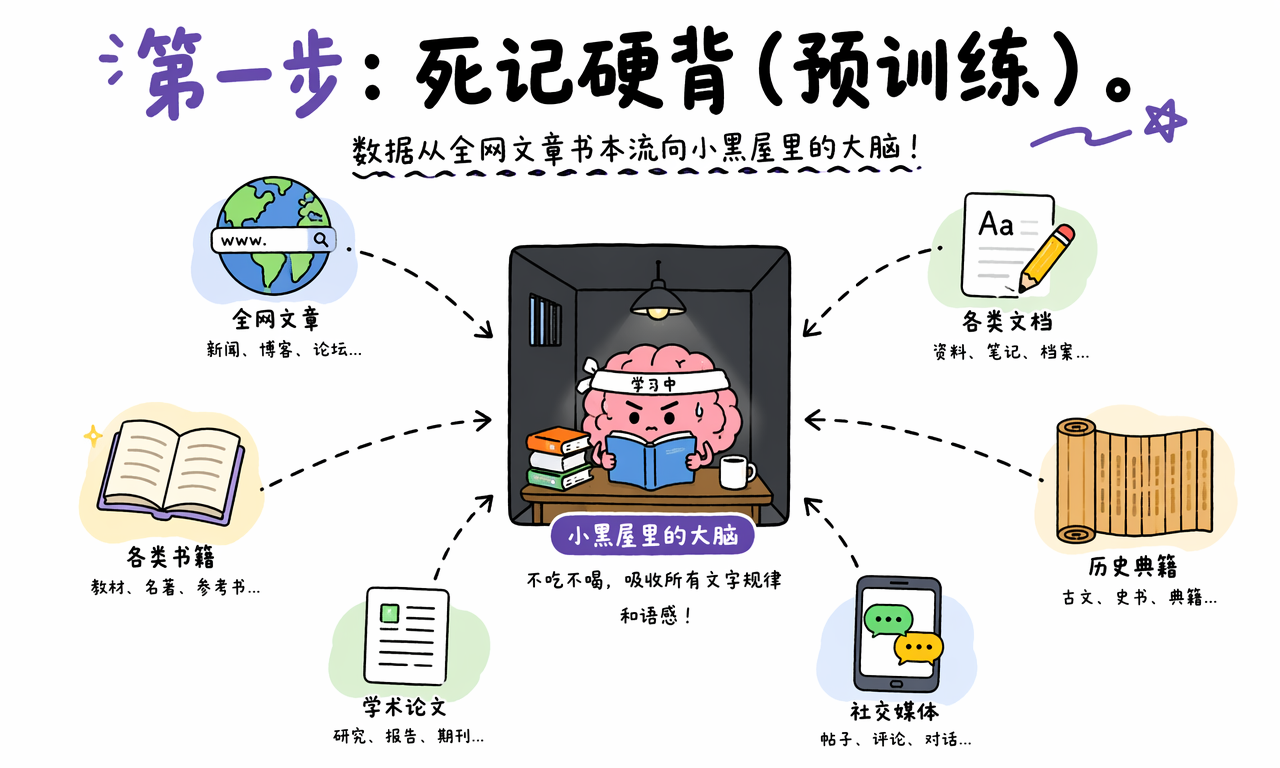
工程师会把海量文本喂给模型。它就像一个被关进小黑屋里的超级学霸,不吃不喝地阅读文章、书本、网页、代码和问答材料,一遍遍观察文字之间的关系。
比如它会学到:
- “床前明月”后面大概率接“光”。
- “今天天气很好,所以我想”后面可能接“出去走走”。
- “这段代码报错的原因可能是”后面通常会进入解释和排查。
- “请用三点总结”后面应该生成结构化列表。
预训练并不是把所有资料原封不动存在数据库里。更准确地说,模型会把这些文本规律压缩进巨量参数里。参数就像它脑子里的神经连接,记录着“哪些词经常一起出现”“哪些概念有关系”“什么语气适合什么场景”。
所以,LLM 不是传统意义上的搜索引擎。搜索引擎更像图书馆管理员,帮你找原文;大语言模型更像读过很多书的学霸,凭语感和知识关联现场组织答案。
第二步:推理预测,超级高科技文字接龙
当你真正向 LLM 提问时,它进入第二步:推理预测。
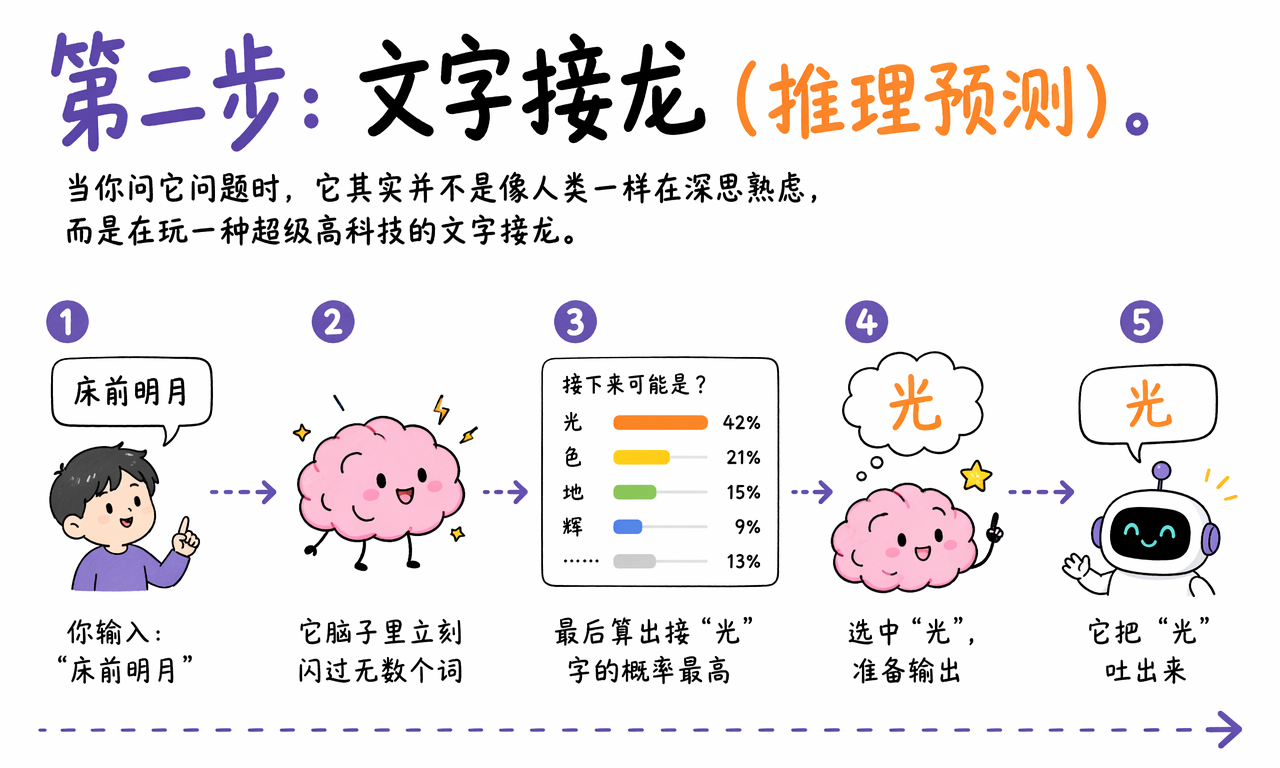
这一步看起来像思考,其实底层更像超级高科技版文字接龙。
你输入“床前明月”,模型会把这几个字转换成 token,再把它们送进神经网络。网络经过一层层计算后,会输出一个巨大的概率表:下一个 token 可能是什么,每个候选项的概率有多高。
在这个例子里,“光”的概率会非常高。于是模型把“光”吐出来。
但真实聊天当然比古诗接龙复杂得多。你问它“帮我解释一下 LLM”,它要同时考虑问题主题、上下文、语气、你可能的知识水平、回答结构,以及哪些信息应该先讲、哪些信息应该后讲。
从工程视角看,它仍然是在做同一件事:根据当前上下文,预测下一个最合适的 token。
第三步:文本生成,像挤牙膏一样往外蹦
模型不是一次性把整篇文章“想好”再吐出来,而是一个 token 接一个 token 地生成。
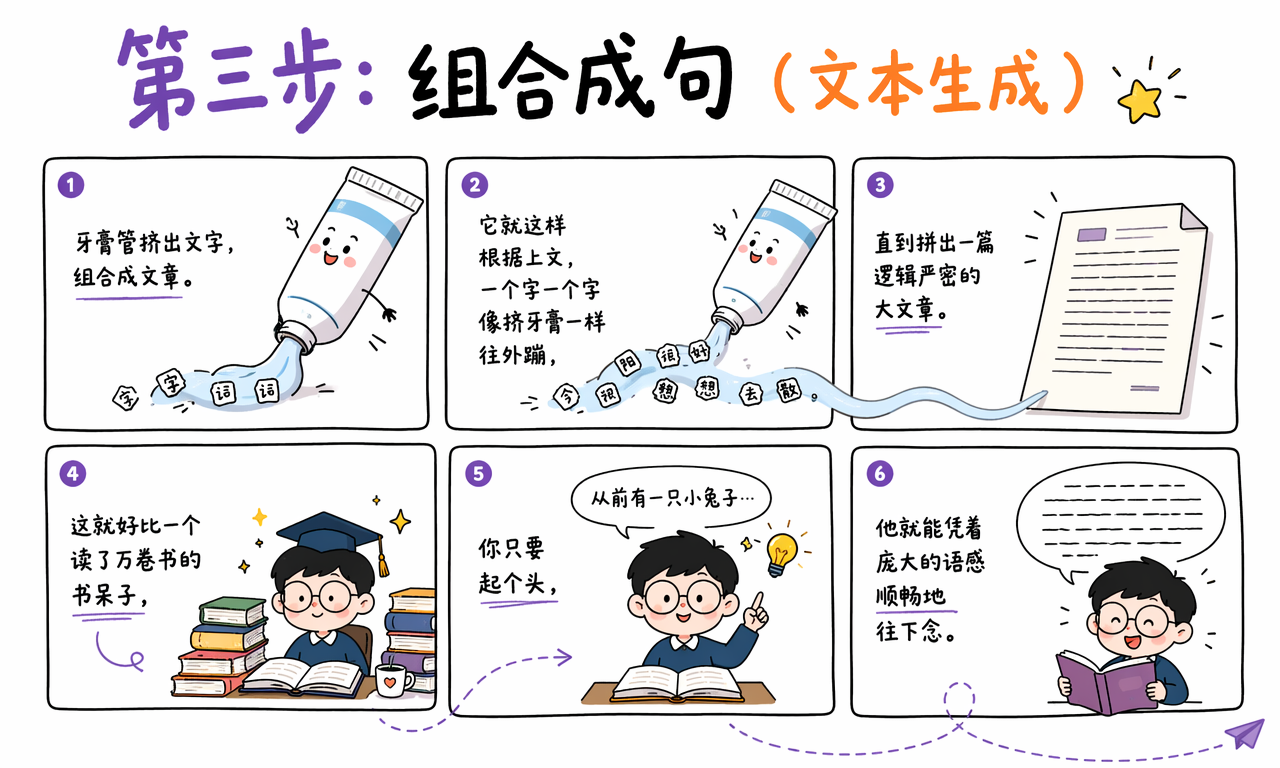
它先根据你的问题预测第一个 token,再把这个 token 加回上下文,继续预测第二个 token。第二个出来后,又继续预测第三个。如此循环,直到生成完整回答,或者达到停止条件。
这就像一个读了万卷书的书呆子,你只要起个头,他就能凭着庞大的语感顺畅往下念。
不过,模型生成文本时并不总是选择概率最高的那个 token。很多系统会加入温度、采样、top-k、top-p 等策略,让回答既合理又不至于每次都一模一样。
温度越低,模型越保守,回答更稳定;温度越高,模型越发散,创意更多,但胡说八道的风险也更高。
如果超级大脑开始一本正经胡说八道呢
这时,一个极端问题就来了:如果这个“超级最强大脑”读书读傻了,开始一本正经地胡说八道怎么办?

这类问题通常被叫做幻觉。模型可能把不确定的信息说得很肯定,也可能把两个相似概念混在一起,还可能编出看起来像真的书名、论文、链接或数据。
另一个风险更严重:如果它学到了网上的坏心思,开始生成危险建议、攻击步骤、违法内容,或者被用户诱导绕开规则怎么办?
这说明一个事实:只靠预训练出来的模型,还只是野蛮生长的“高分书呆子”。它会说话,但不一定可靠;它知识多,但不一定知道什么该说、什么不该说。
RLHF:给书呆子配一个选秀裁判
为了让大语言模型更符合人类偏好,工程师会引入一类关键机制:RLHF,也就是人类反馈强化学习。
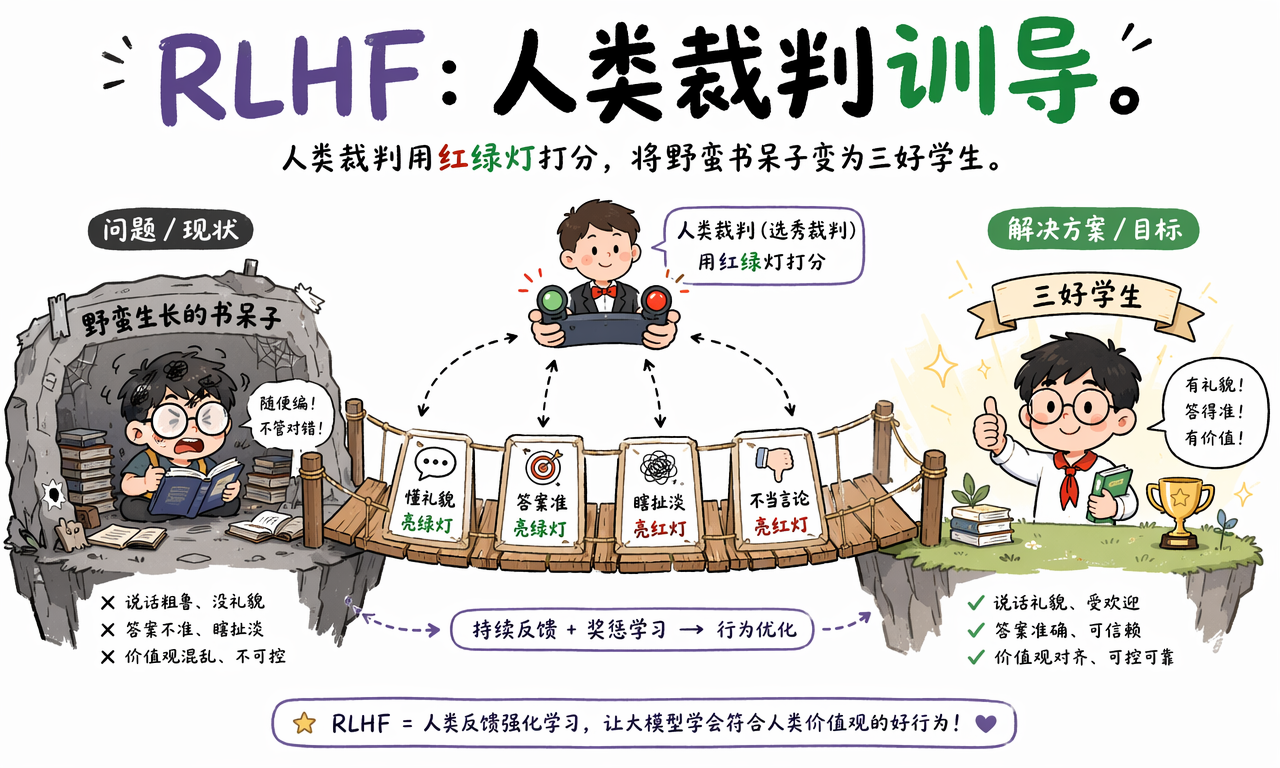
你可以把它想象成:给小黑屋里的书呆子配上一个手握按键器的选秀裁判。
模型给出多个回答后,人类标注员会评价哪个更好:哪个更准确,哪个更礼貌,哪个更有帮助,哪个有风险,哪个在瞎扯。高质量回答亮绿灯,低质量回答亮红灯。
这些反馈会被训练成奖励模型,再用强化学习或类似的对齐方法,继续调整大语言模型的行为。久而久之,它就会更倾向于输出人类喜欢的答案。
所以,一个对话式 LLM 通常不是只经过“读书”这一步。它往往经历了预训练、指令微调、人类偏好对齐、安全策略约束等多个阶段,才从野蛮生长的书呆子变成比较会沟通的“三好学生”。
当然,RLHF 不是万能保险。它能显著改善模型行为,但不能保证模型永远不犯错。重要场景里,仍然需要事实校验、权限控制、人工复核和安全边界。
它已经接进了你的工作流
其实,这个超级大脑早就无缝接入了咱们的日常工作。
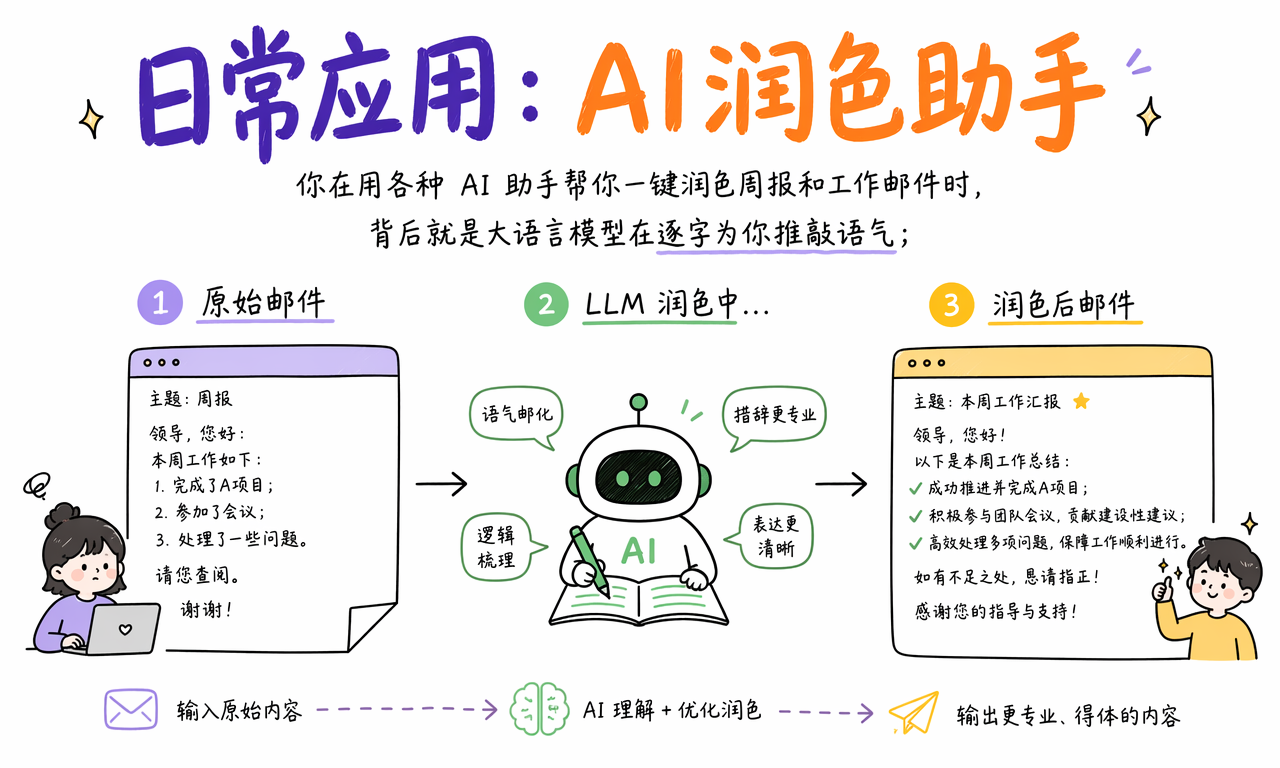
你用各种 AI 助手一键润色周报和工作邮件时,背后就是大语言模型在逐字推敲语气。它会判断这句话是不是太生硬,那个词是不是太口语,整封邮件是不是既礼貌又不啰嗦。
这类能力看似简单,实际上依赖模型对商务表达、上下文关系和语气分寸的综合判断。
它正在重写翻译体验
你用翻译软件把一篇全英文长文瞬间变成通顺中文时,背后也有大语言模型的影子。
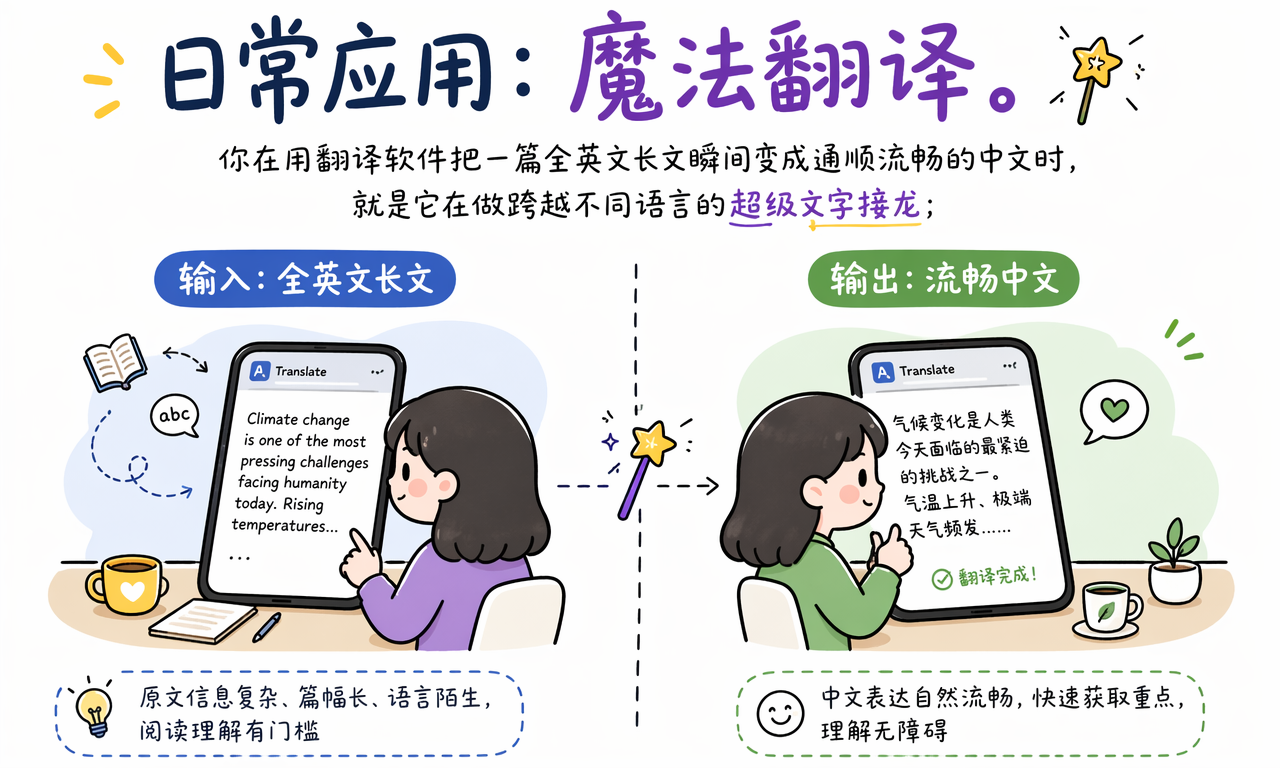
传统机器翻译更像逐句对照,容易翻得僵硬。大语言模型则更擅长理解上下文:这句话是在铺垫、转折、解释,还是强调?这个专业词该直译,还是换成中文语境里更自然的说法?
所以,好的 LLM 翻译不只是把英文词换成中文词,而是在另一种语言里重新生成一段意思一致、读起来顺畅的文本。
它也在帮你压缩信息
你在长视频网站里看到“AI 一键总结视频省流版”时,也是大语言模型在干活。
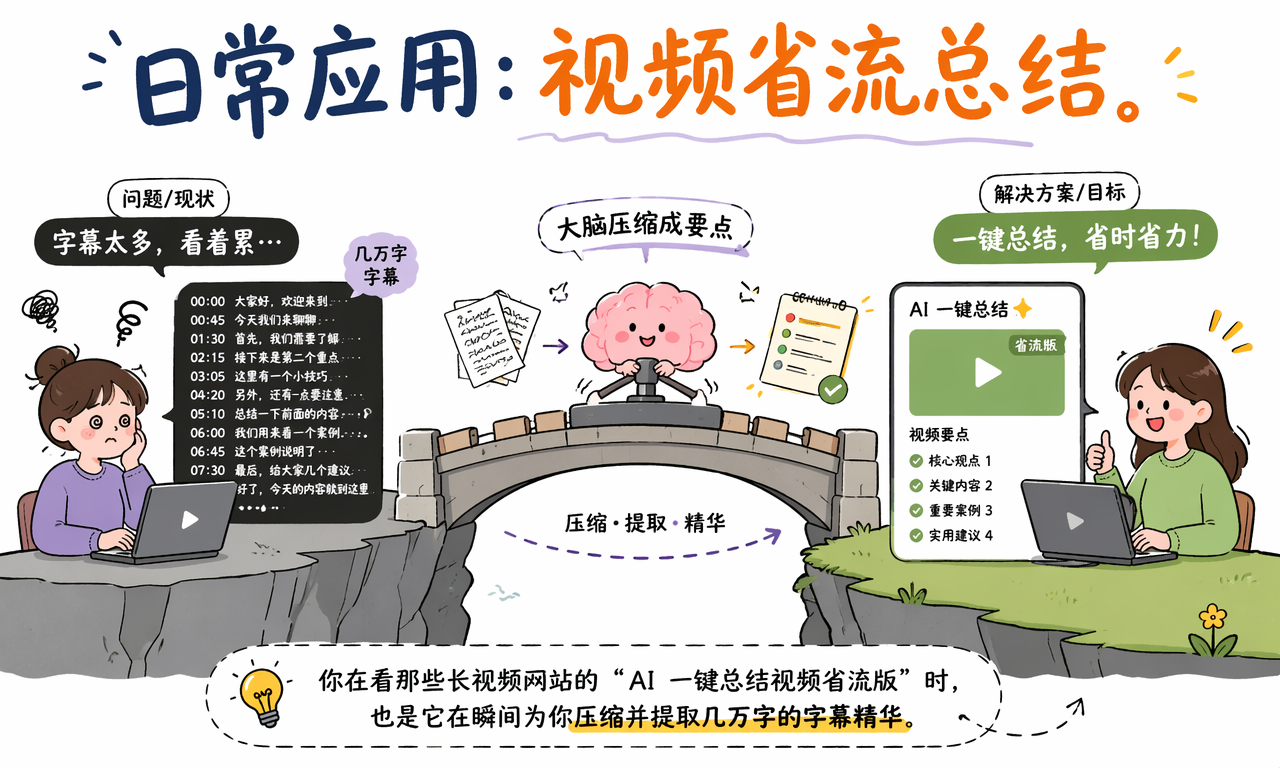
一个几十分钟的视频,可能对应几万字字幕。模型会先读完整段文本,再判断哪些是核心观点、哪些是例子、哪些是重复表达,最后把它压缩成几段摘要或几个要点。
这背后的本质,仍然是语言理解和语言生成:先读懂,再重组。
从工作邮件、论文阅读、会议纪要,到客服问答、代码解释、智能搜索,大语言模型已经变成很多软件里的底层能力。你未必每次都看见它,但经常已经在使用它。
总结:它是生成式 AI 时代的起点
总结一下,大语言模型就是一个被关在小黑屋里、读过海量文本的超级学霸。
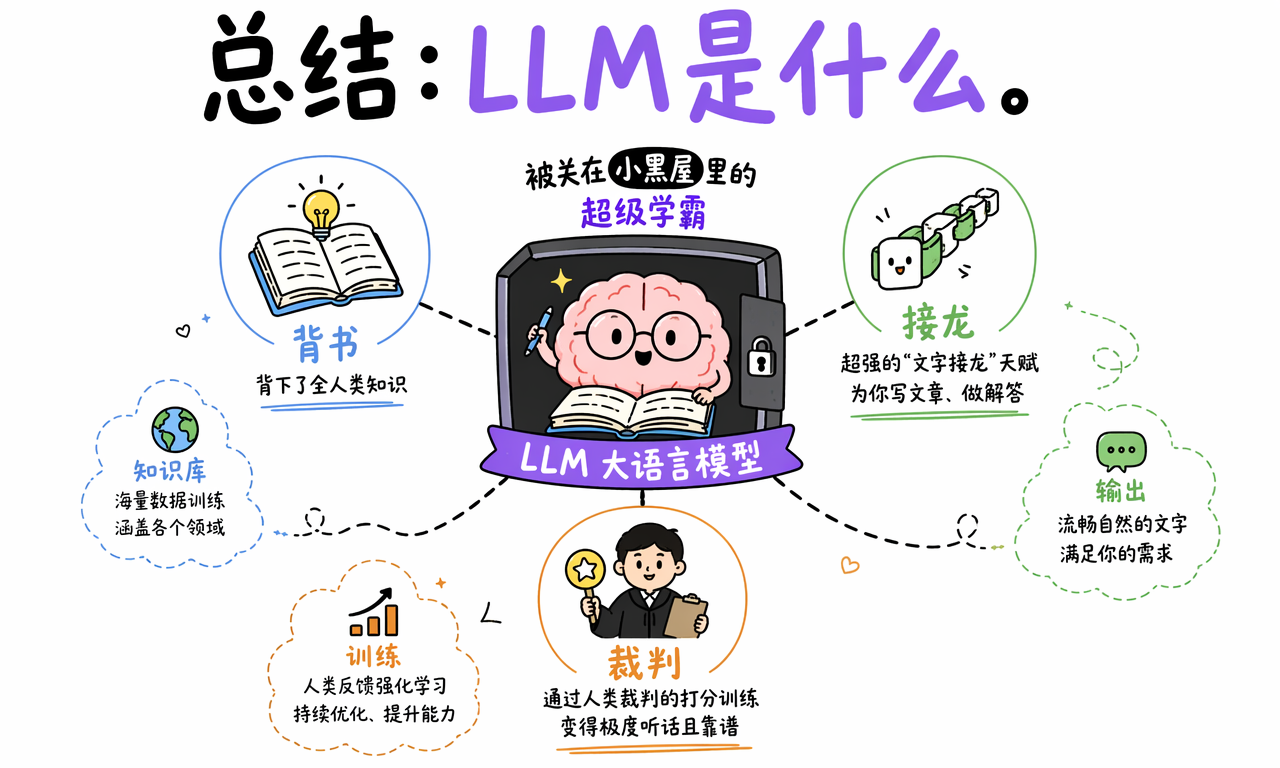
它先通过预训练吞下大量人类文字,学会语言规律和知识关联;再在推理阶段通过“预测下一个 token”进行文字接龙;最后通过一个 token 接一个 token 的生成方式,拼出看起来连贯、有逻辑、有风格的回答。
为了让它别变成一本正经胡说八道的书呆子,工程师还会用人类反馈、指令微调和安全策略,把它训练得更有用、更可靠、更听话。
它把“机器只能听懂死板代码的冰冷状态”,推进到了“机器能流畅理解自然语言的智能状态”。
理解 LLM,就是理解生成式 AI 时代的起点。因为今天的 AI 助手、智能搜索、自动写作、代码生成、视频总结、翻译润色,很多能力都建立在同一个核心之上:让机器学会用人类语言理解世界、组织信息,并把答案说出来。