
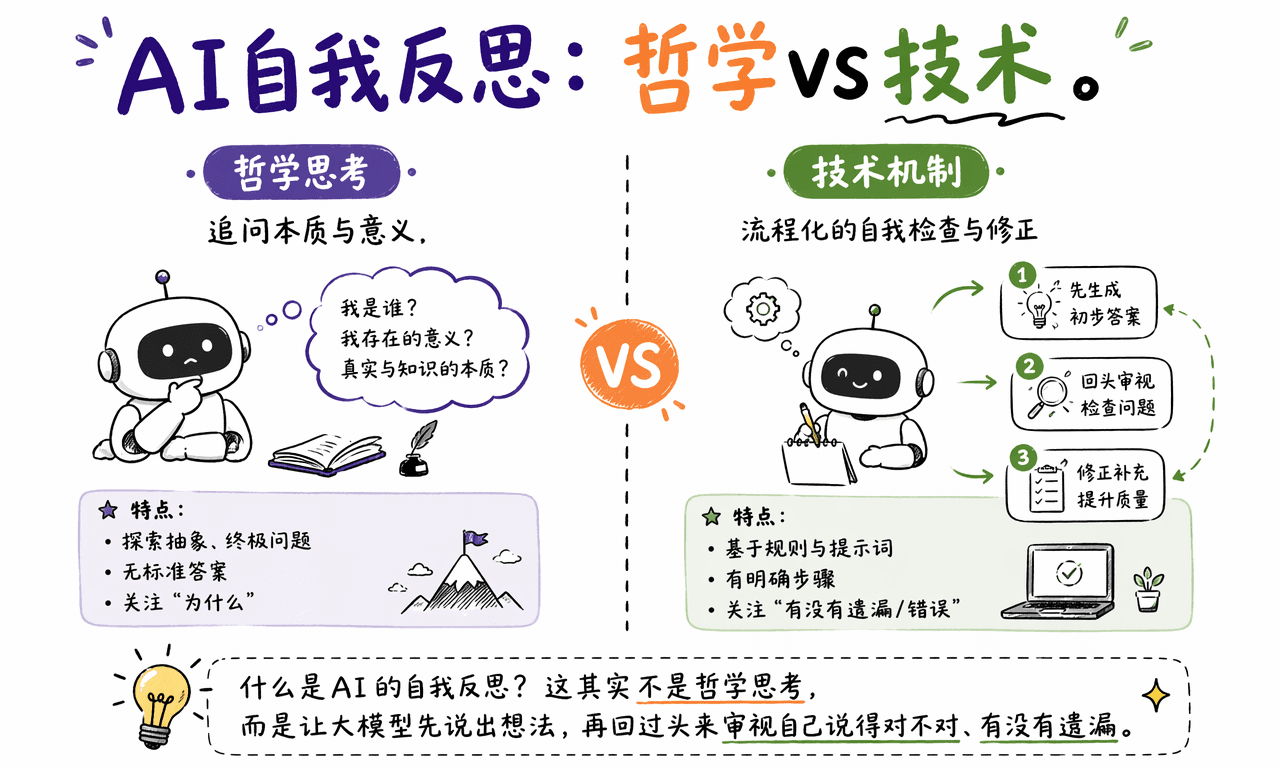
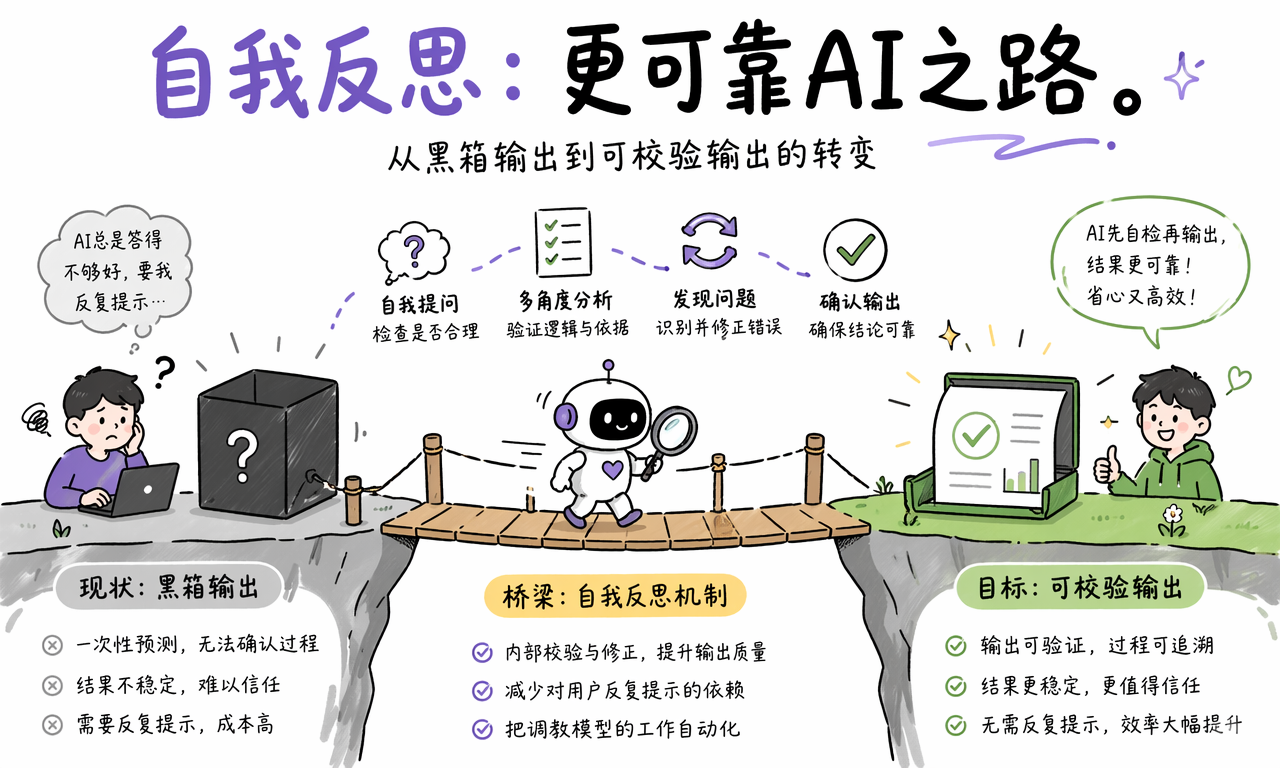
AI 自我反思是什么
AI 自我反思,也叫 Reflection,是一种让大语言模型在生成初始答案之后,再生成自我反馈,并基于反馈修正答案的推理技术。它不是哲学意义上的“自我意识”,而是一套自动化的生成、检查和改写流程。
更具体地说,Reflection 包含三个动作:先回答、再挑错、最后重写。模型会检查初稿里是否有事实错误、逻辑断点、格式偏差、遗漏要求或不合适的语气,然后把这些问题转化成修改指令。
一句话定义:AI 自我反思是把原本一次性的“输入到输出”,改造成“生成、反馈、修正”的循环。
为什么用户会需要 AI 自我反思
用户需要 AI 自我反思,是因为大模型的第一版答案经常足够快,但不一定足够稳。复杂任务里,第一版输出可能语气不对、卖点不完整、事实没核实,甚至编出用户没有提供的功能。
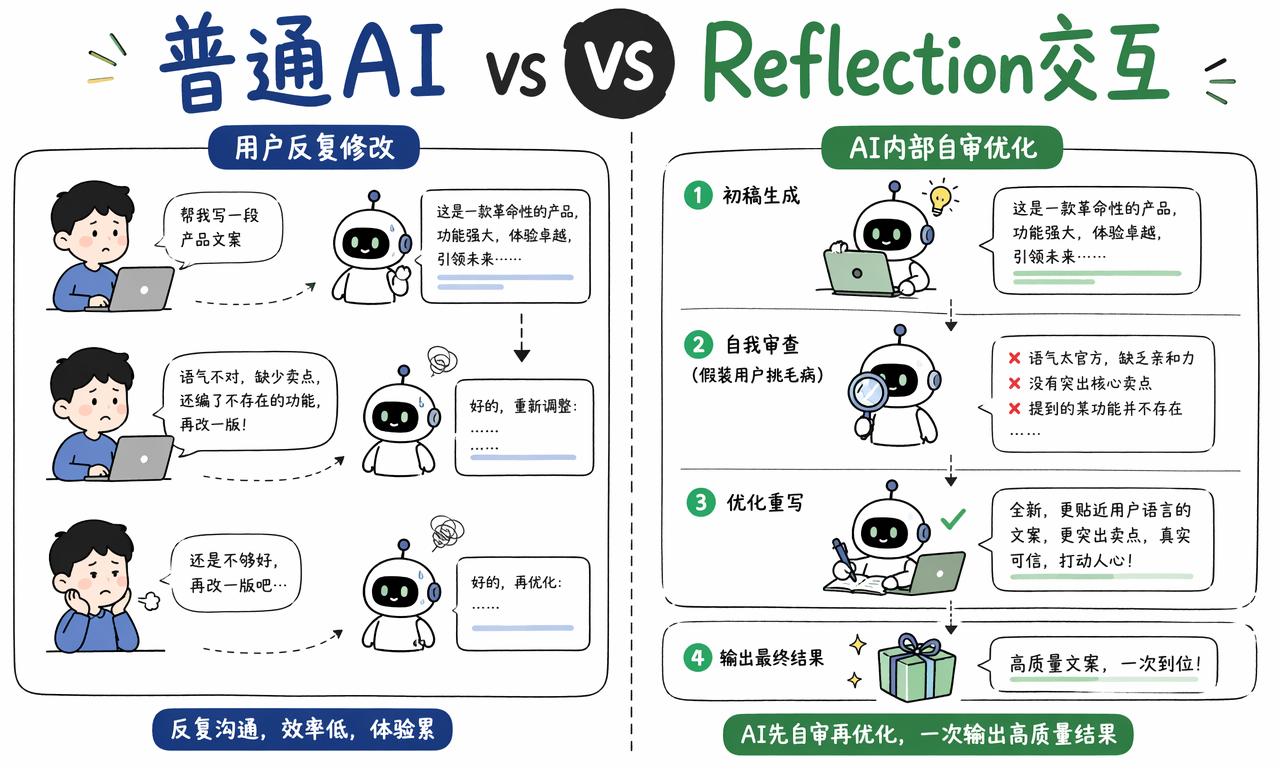
一个常见场景是产品文案。你让 AI 写一段新品介绍,它很快给出结果,但你一看会发现三个问题:
- 语气不像目标品牌。
- 没有突出核心卖点。
- 额外写了一个产品并不存在的功能。
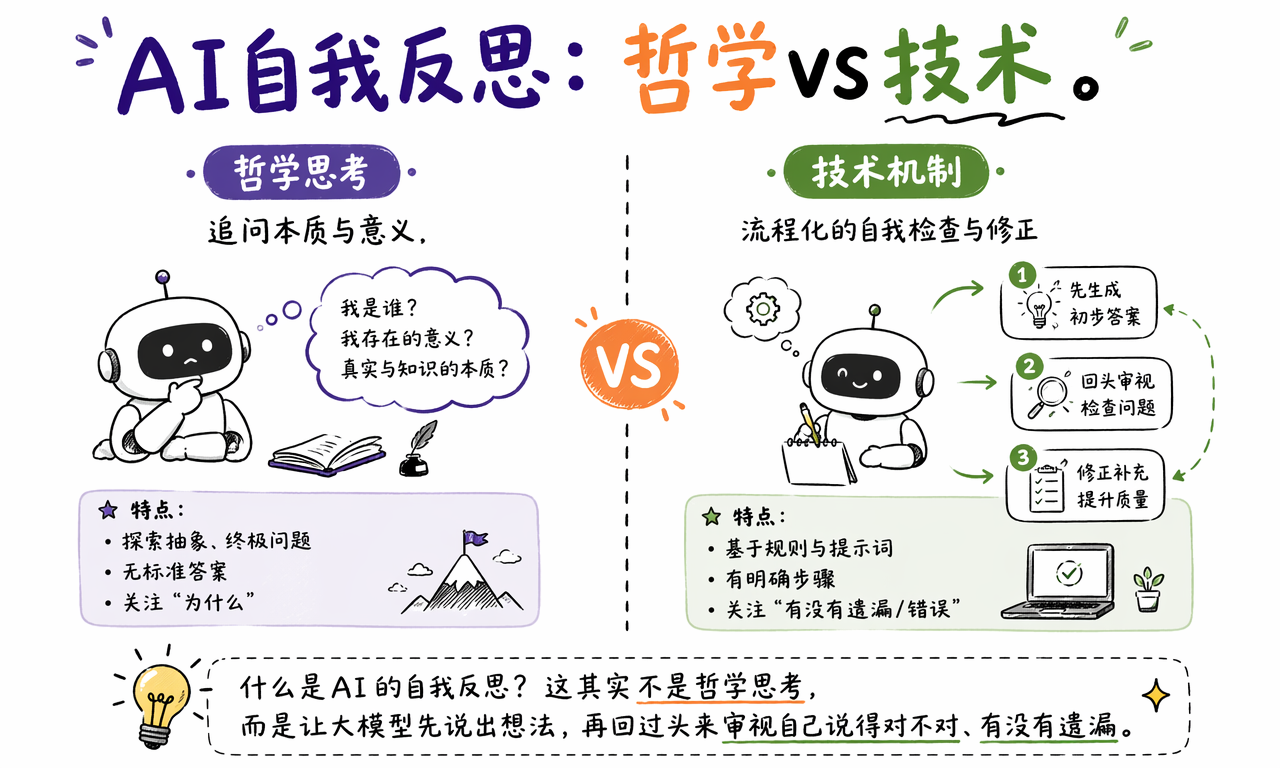
普通用法是用户继续说“再改一版”,把要求重新解释一次。Reflection 的思路不同:在答案交给用户之前,模型自己先做一轮内部审查。它相当于先假装自己是挑剔用户,把第一版答案的问题列出来,再根据问题生成最终版本。
因此,Reflection 的价值不是让 AI 多写几句话,而是把一部分原本由用户承担的复核工作自动化。
Reflection 的核心流程是什么
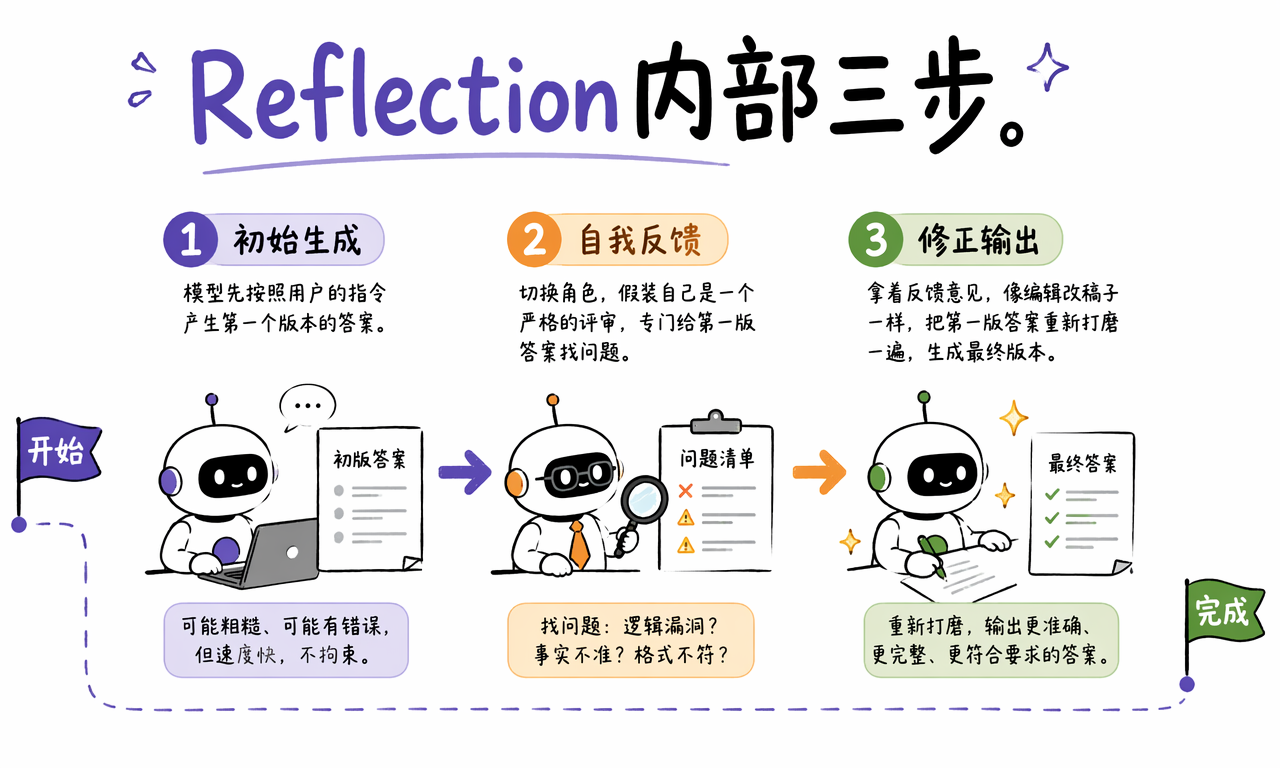
Reflection 的核心流程可以拆成三步:初始生成、自我反馈、修正输出。这个顺序很重要,因为模型必须先有一个可检查的草稿,才能对草稿提出具体改进意见。
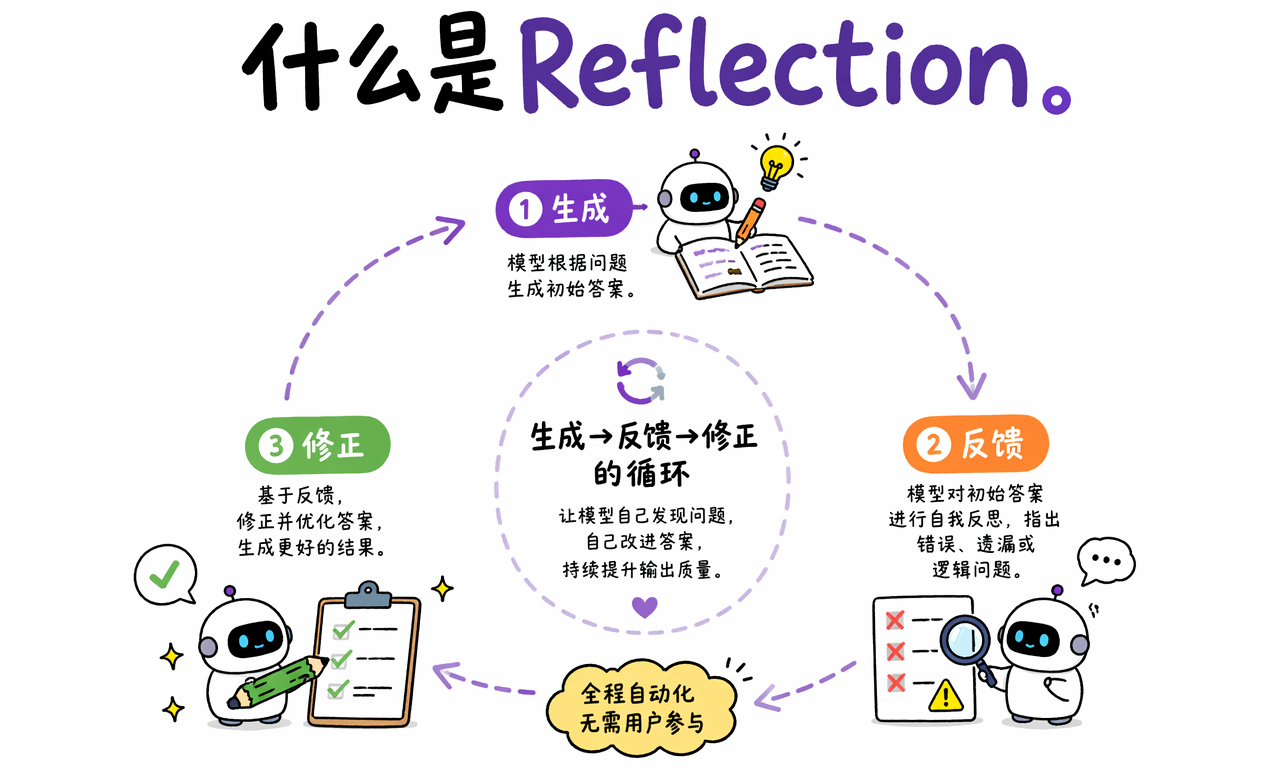
- 初始生成:模型按照用户指令生成第一版答案。这个版本可能粗糙,但能快速形成完整草稿。
- 自我反馈:模型切换到评审角色,检查第一版是否准确、完整、清晰、符合格式要求。
- 修正输出:模型把反馈意见作为编辑指令,重新生成更稳的最终答案。
这个流程可以只跑一轮,也可以多轮迭代。多轮迭代能继续提升质量,但会增加 token 消耗和响应时间。
为什么 Reflection 能让回答更可靠
Reflection 能提高回答可靠性,是因为它给模型增加了“事后检查”的机会。大模型生成文本时通常是按 token 向后预测,前面一句话一旦偏离目标,后面内容可能继续沿着错误方向展开。
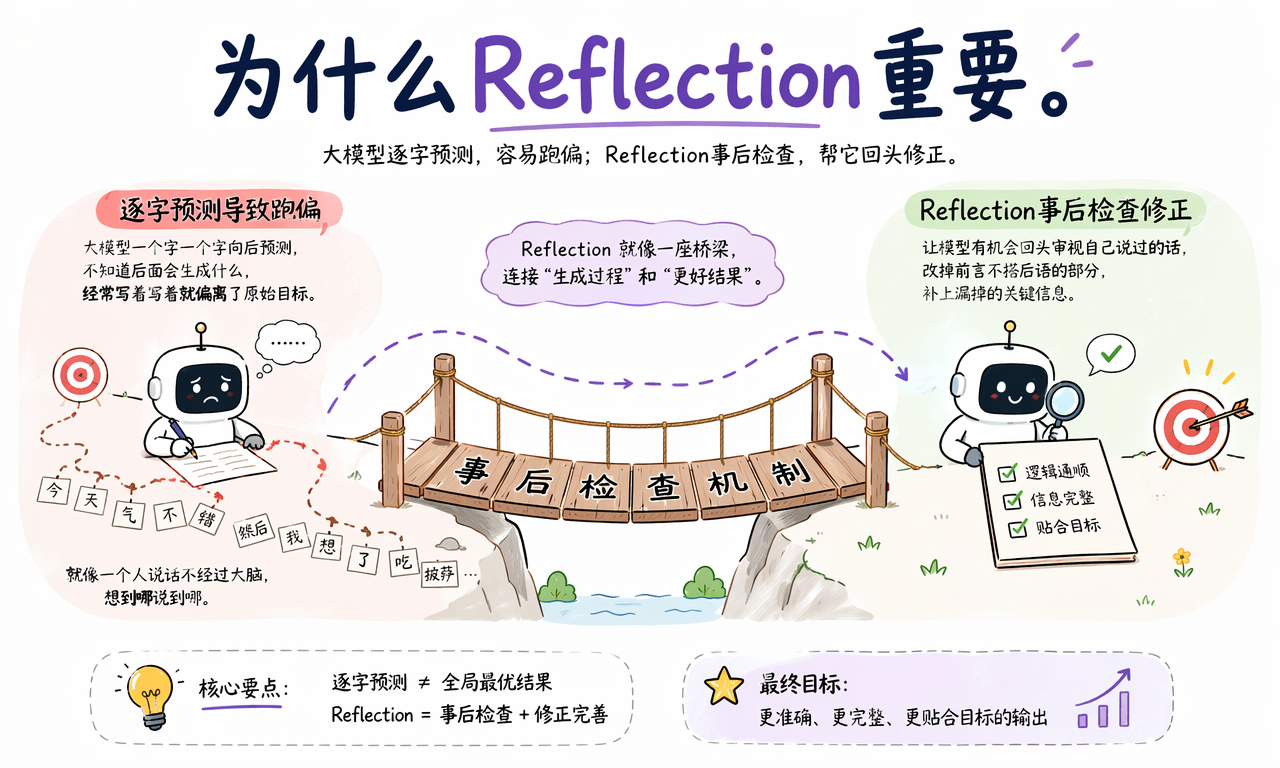
没有反思时,模型更像线性写作:看到提示词后直接从开头写到结尾。这个过程速度快,但容易遗漏约束,也不容易主动回看前文。
有反思时,模型会把第一版答案当作审查对象。它可以发现:
- 前后说法是否矛盾。
- 是否遗漏了用户明确要求。
- 是否有未经证实的事实。
- 输出格式是否符合任务。
- 语气、受众和使用场景是否匹配。
所以 Reflection 的本质不是“模型突然更聪明”,而是让模型在推理时多了一道质量控制环节。
AI 自我反思内部怎么运作
AI 自我反思通常由生成器、评审器和改写器三个角色组成。这三个角色可以由同一个模型通过不同提示词扮演,也可以由多个模型或外部工具分工完成。
| 组件 | 负责什么 | 常见实现方式 |
|---|---|---|
| 生成器 | 生成第一版答案 | 普通 LLM 调用或初始 Prompt |
| 评审器 | 找出错误、遗漏和不符合要求的地方 | 自评 Prompt、评分规则、测试用例、检索工具 |
| 改写器 | 根据反馈修正答案 | 同一模型重写,或更强模型二次加工 |
| 停止条件 | 判断是否继续反思 | 固定轮数、评分阈值、测试通过、用户预算 |
在简单产品里,这个流程可能只是一个提示词模板。在复杂 Agent 系统里,它可能会接入单元测试、数据库查询、搜索引擎、代码执行器或业务规则引擎。
用代码生成理解 Reflection
代码生成是理解 Reflection 的好例子,因为代码质量可以被测试、类型检查和运行结果验证。反思不只是在语言上“觉得更好”,还可以通过工具检查发现真实错误。
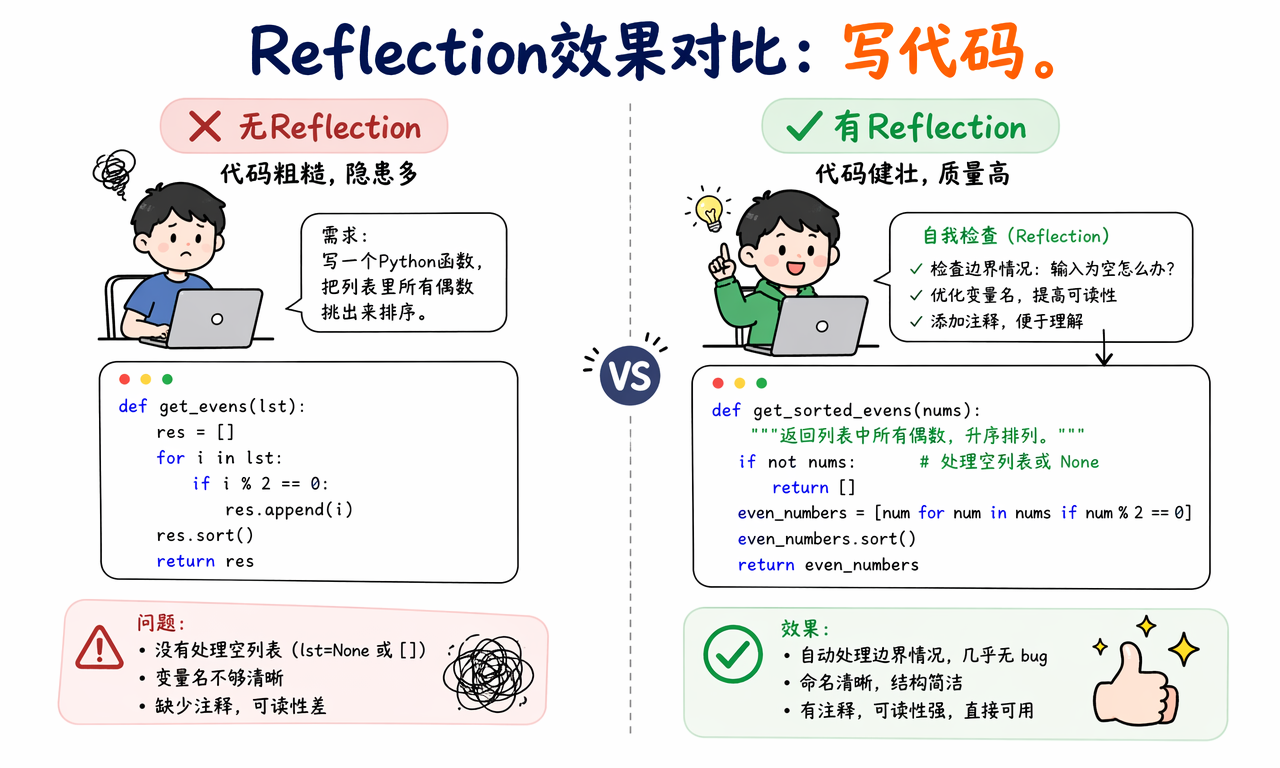
假设用户要求:
写一个 Python 函数,把列表里的所有偶数挑出来并排序。
没有 Reflection 时,模型可能直接给出:
def get_even_numbers(nums):
return sorted([x for x in nums if x % 2 == 0])
这段代码能处理多数普通输入,但如果产品要求更严格,还需要考虑输入为空、输入不是列表、元素不是整数等边界。开启 Reflection 后,模型的内部反馈可能是:
这段代码能处理空列表,但没有说明输入约束。
如果函数面向通用调用,应明确只接受整数列表,或者对非整数元素做过滤。
变量名可以更明确,函数名也可以表达排序行为。
修正后的版本可能变成:
def sorted_even_numbers(numbers: list[int]) -> list[int]:
"""Return all even integers from numbers in ascending order."""
return sorted(number for number in numbers if number % 2 == 0)
如果再接入测试,Reflection 可以进一步变成“生成代码、运行测试、阅读失败日志、修正代码”的闭环。这个闭环比单纯让模型自夸式复查更可靠。
Reflection 和 CoT、ToT 有什么区别
Reflection、CoT 和 ToT 都是提升大模型推理质量的方法,但它们解决的问题不同。CoT 强调分步推理,ToT 强调多路径搜索,Reflection 强调生成后的自我评审和修正。
| 方法 | 中文名 | 核心动作 | 适合场景 | 主要代价 |
|---|---|---|---|---|
| CoT | 思维链 | 先写中间步骤,再给答案 | 数学题、逻辑题、多步分析 | 输出更长,可能出现虚假推理 |
| ToT | 思维树 | 生成多条候选路径,评估后选择 | 谜题、规划、复杂方案设计 | token 和调用成本高 |
| Reflection | 自我反思 | 先生成答案,再反馈并修正 | 写作、代码、摘要、评审、Agent 任务 | 响应更慢,反馈质量依赖模型能力 |
这三种方法可以组合使用。例如,模型可以先用 CoT 生成分析过程,再用 Reflection 检查过程是否遗漏约束;复杂任务还可以用 ToT 生成多个方案,再用 Reflection 审查最终方案。
Reflection 有哪些常见实现方式
Reflection 的实现方式从简单提示词到完整 Agent 框架都有。选择哪一种,取决于任务风险、预算和是否能用工具验证。
常见方式包括:
- 提示词自评:在提示词里要求模型先检查初稿,再输出最终答案。
- 多答案投票:模型生成多个候选答案,再比较并选择最优版本。
- 评分量表:让模型按准确性、完整性、结构、风格等维度打分。
- 工具验证:调用搜索、计算器、单元测试、类型检查或数据库核实结果。
- 记忆式反思:Agent 把失败经验写入记忆,在下一轮任务中避免重复错误。
研究里的 Self-Refine 就是典型的“初稿、反馈、改写”框架。Reflexion 则强调让 Agent 根据任务反馈生成语言化反思,并把这些反思保存在记忆中,用于后续决策。
Reflection 适合什么场景
Reflection 适合复杂、开放、需要复核的任务,不适合所有任务。判断标准很简单:如果第一版答案经常需要用户改第二版,就值得考虑引入反思。
| 场景 | 是否适合 Reflection | 原因 |
|---|---|---|
| 技术博客写作 | 适合 | 需要检查结构、定义、遗漏、例子和风险说明。 |
| 代码生成 | 适合 | 可以结合测试、类型检查和边界条件审查。 |
| 长文摘要 | 适合 | 需要核对关键事实、数字和结论是否遗漏。 |
| 产品文案 | 适合 | 需要检查卖点、语气、受众和事实边界。 |
| Agent 执行任务 | 适合 | 可以让 Agent 从失败步骤中生成下一轮策略。 |
| 简单翻译 | 通常不适合 | 直接生成成本更低,反思收益有限。 |
| 闲聊问候 | 不适合 | 任务风险低,额外延迟没有必要。 |
一句话判断:高价值任务需要 Reflection,低风险任务不一定需要 Reflection。
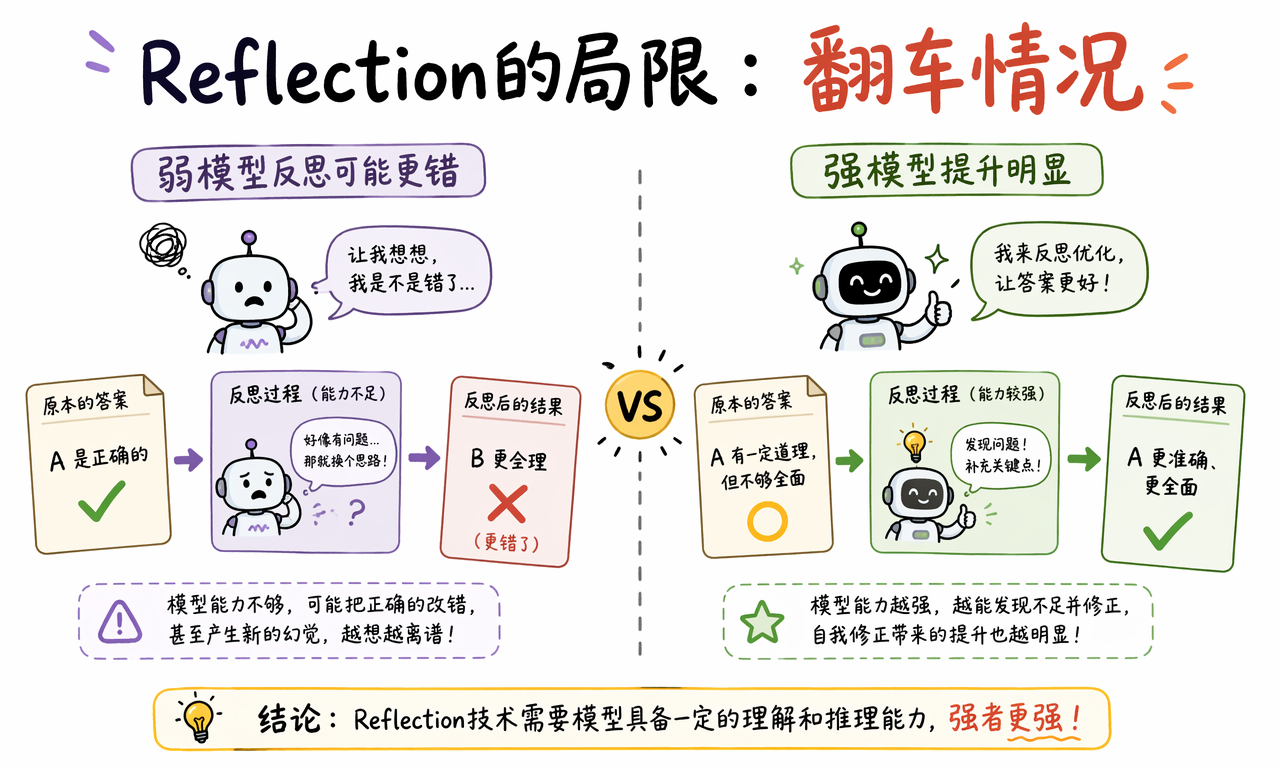
Reflection 的限制和翻车点是什么
Reflection 不是银弹。它能改善很多输出问题,但不能保证事实正确,也不能把弱模型自动变成强模型。
主要限制有四类:
- 模型能力限制:如果模型本身理解能力不足,它可能把正确答案改错。
- 自评不可靠:模型可能看不出自己的幻觉,还会为错误解释找理由。
- 缺少外部知识:高度依赖实时信息、专业数据或私有上下文的任务,不能只靠自我反思。
- 目标函数不清楚:如果用户没有给出明确标准,模型可能按错误标准优化。
最危险的情况是“错得更像真的”。反思后的答案通常更完整、更自信,但完整和自信不等于正确。面对法律、医疗、金融、安全工程和生产系统操作,Reflection 必须和事实检索、工具验证或人工审查结合使用。
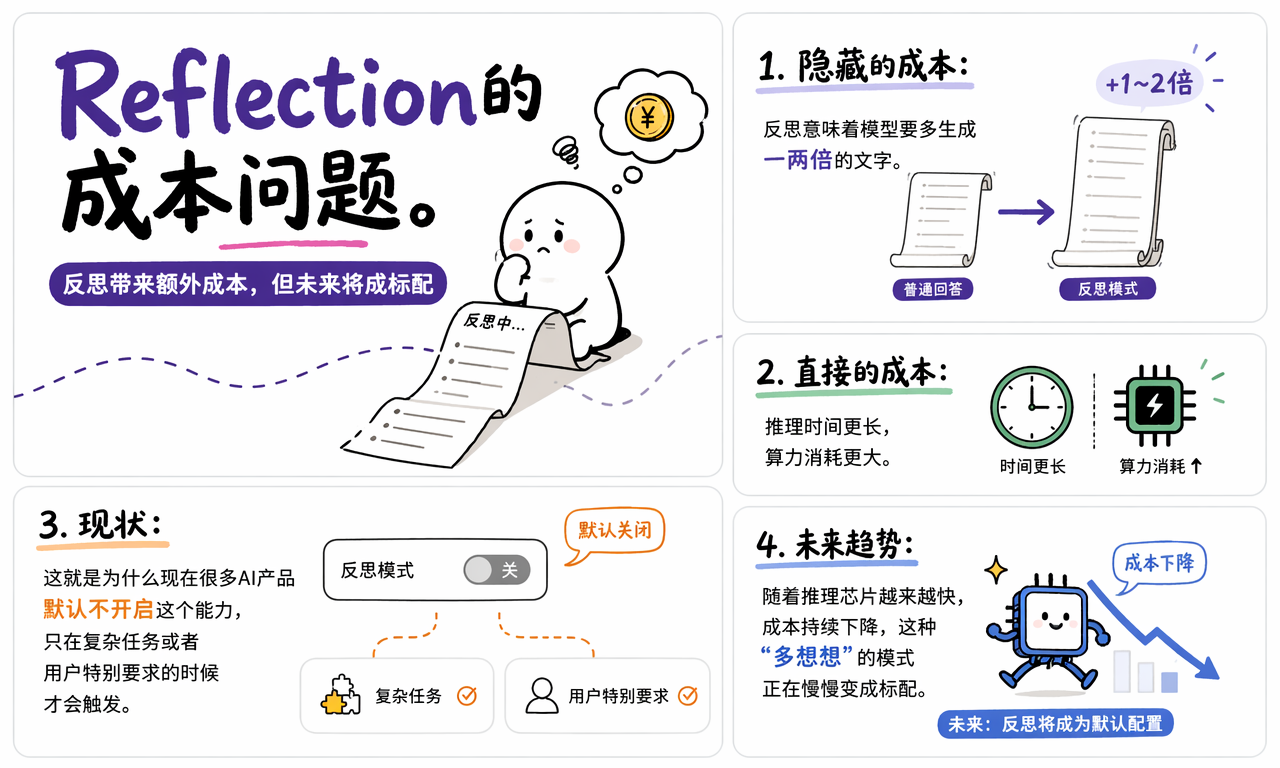
Reflection 的成本是什么
Reflection 的主要成本是时间、token 和系统复杂度。模型多做一轮反馈和修正,就意味着多生成一段文本、多消耗一次推理预算,并让用户等待更久。
成本可以分成三层:
| 成本类型 | 具体表现 | 降低成本的方法 |
|---|---|---|
| 时间成本 | 响应从一次生成变成两次或多次生成 | 只在复杂任务触发反思 |
| token 成本 | 需要额外生成反馈和修正版 | 限制反馈长度,使用结构化检查清单 |
| 工程成本 | 需要编排多轮模型调用和工具验证 | 把反思流程封装成可复用模块 |
| 体验成本 | 用户可能感觉系统“停顿几秒” | 在界面上显示正在检查或验证 |
这也是很多 AI 产品不会对所有请求默认开启 Reflection 的原因。更常见的做法是:简单任务直接回答,复杂任务、代码任务、高风险任务才触发反思。
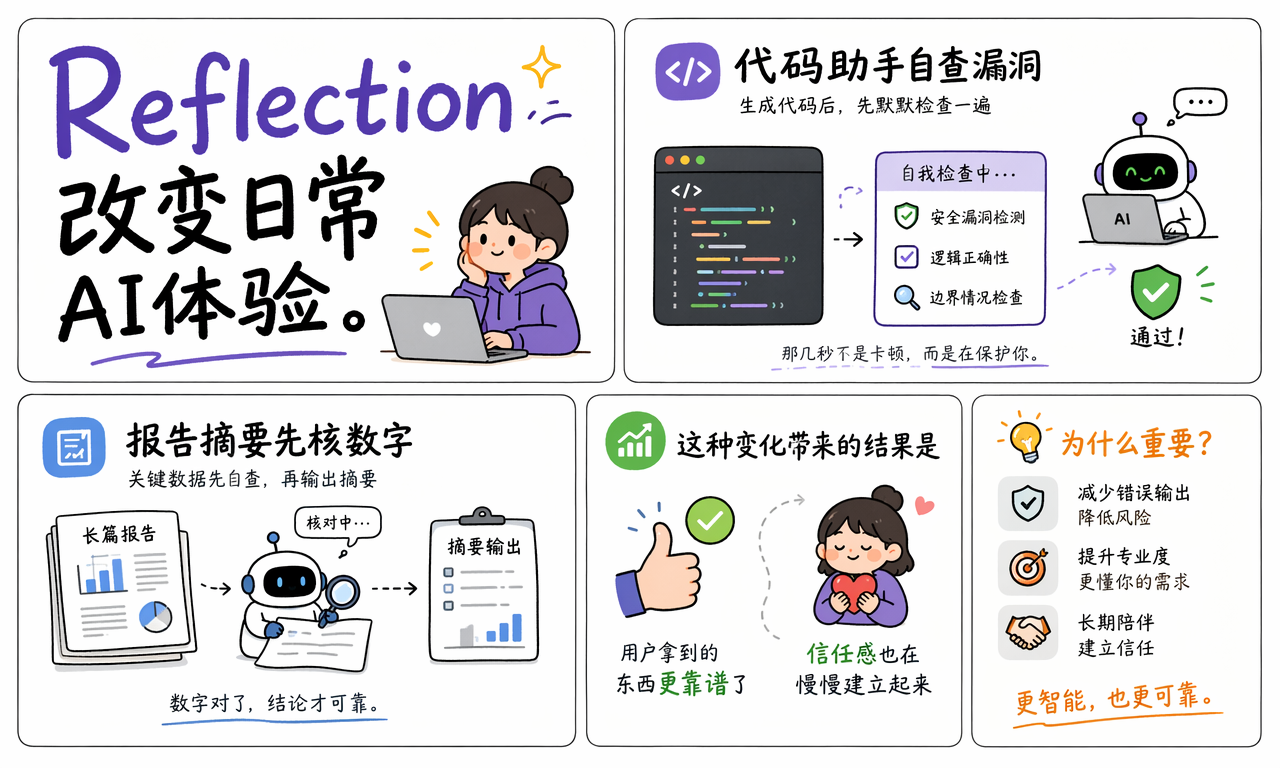
Reflection 会如何改变 AI 产品交互
Reflection 会让 AI 产品从“快速回答器”变成“带内部审查的协作者”。用户看到的可能只是结果更稳,但系统内部已经多了一层检查、反馈和修正流程。
在代码助手里,模型生成代码后可能会沉默几秒。那几秒不一定是卡顿,而可能是在检查潜在 bug、安全问题、边界条件或测试失败原因。
在文档助手里,模型总结长篇报告前可能会先核对关键数字、人物关系和结论是否一致。
在客服 Agent 里,模型回复用户前可能会先检查答案是否违反政策、是否遗漏订单信息、是否需要转人工。
这种变化会降低用户反复提示的成本。用户不必每次都说“再检查一下”“有没有遗漏”“格式不对再改”,因为系统可以把这些动作内置进生成流程。
如何写一个简单的 Reflection 提示词
一个实用的 Reflection 提示词应该明确任务、检查标准和最终输出格式。不要只写“请反思一下”,而要告诉模型检查什么。
请完成下面任务,并在最终回答前做一轮自我检查。
任务:{你的任务}
自我检查标准:
1. 是否完整回答了用户问题。
2. 是否存在事实不确定或需要标注的信息。
3. 是否有逻辑跳跃、前后矛盾或遗漏约束。
4. 是否符合指定格式和目标受众。
请不要输出冗长的内部过程。
最终只输出修正后的答案,并在末尾用 3 条以内列出关键检查点。
如果任务可以验证,提示词还应该加入外部检查:
如果你生成代码,请先给出代码,再根据边界条件列出测试用例。
如果发现代码无法通过测试,请修正后再输出最终版本。
好的 Reflection 提示词不是让模型“想得更玄”,而是把质量标准写清楚。
常见问题
AI 自我反思是让模型拥有自我意识吗?
不是。AI 自我反思不是自我意识,也不是哲学思考。它是一种工程流程:模型先生成答案,再根据提示词、评分标准或工具反馈检查并修正答案。
Reflection 和 Self-Refine 是一回事吗?
Self-Refine 是 Reflection 思路的一种典型实现。它让同一个语言模型生成初稿、提供反馈、再根据反馈改写,并可以重复多轮。
Reflexion 和 Reflection 有什么区别?
Reflection 是泛称,指模型的自我反馈和自我修正机制。Reflexion 是一篇研究工作和框架名称,强调语言 Agent 根据任务反馈生成反思文本,并把反思写入记忆以改进后续任务。
Reflection 能完全解决 AI 幻觉吗?
不能。Reflection 能降低遗漏、格式错误和部分逻辑问题,但不能保证事实正确。事实类问题仍然需要检索、引用、数据库、测试或人工审查。
为什么很多 AI 产品不默认开启 Reflection?
因为 Reflection 会增加响应时间、token 成本和系统复杂度。产品通常会在代码生成、复杂分析、长文总结、高风险回答等场景触发反思,而不是对所有闲聊请求都启用。
普通用户怎么手动使用 Reflection?
普通用户可以在提示词里加入检查标准,例如“先写一版,再从准确性、完整性、逻辑和格式四个角度检查,最后只输出修正版”。任务越复杂,检查标准越应该具体。
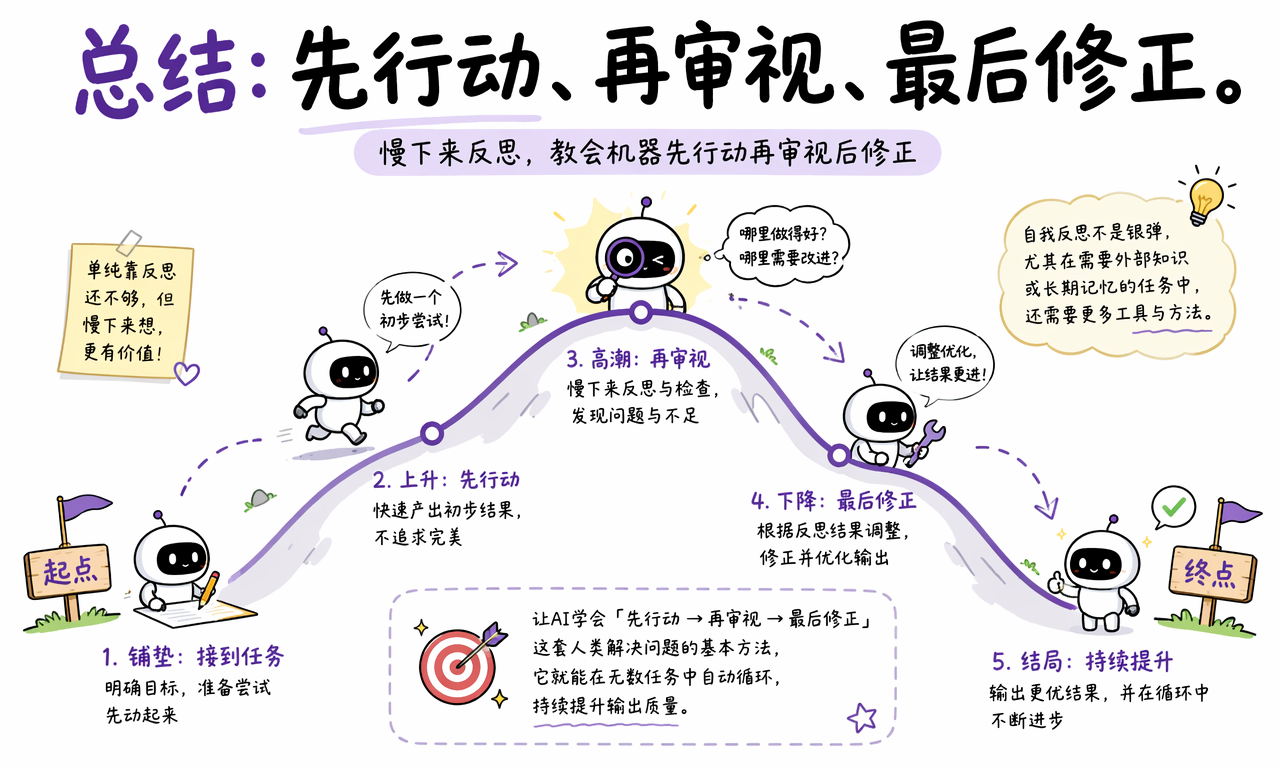
总结
AI 自我反思是一种让大语言模型先生成、再反馈、最后修正的推理技术。它把一次性回答变成可检查、可迭代、可接入工具验证的工作流。
Reflection 的实际价值,是让 AI 在交付答案前先做一部分用户本来要做的复核工作。它特别适合代码生成、复杂写作、长文摘要、方案评审和 Agent 执行任务。
但 Reflection 不是万能药。它依赖模型本身的理解能力,也会增加时间和算力成本;遇到外部事实、实时数据和高风险决策时,仍然需要工具验证和人工判断。
让 AI 慢下来想一想,通常比让它更快地抢答更有价值。Reflection 把“先行动、再审视、最后修正”这套人类解决问题的基本方法,变成了机器可以重复执行的生成流程。