

什么是 Token
Token 是大模型处理信息的最小计算单位。它不是完整的单词,不一定是单个汉字,也不等于屏幕上的一个 emoji,而是文本、图像、声音或代码被模型切分后得到的数字化片段。
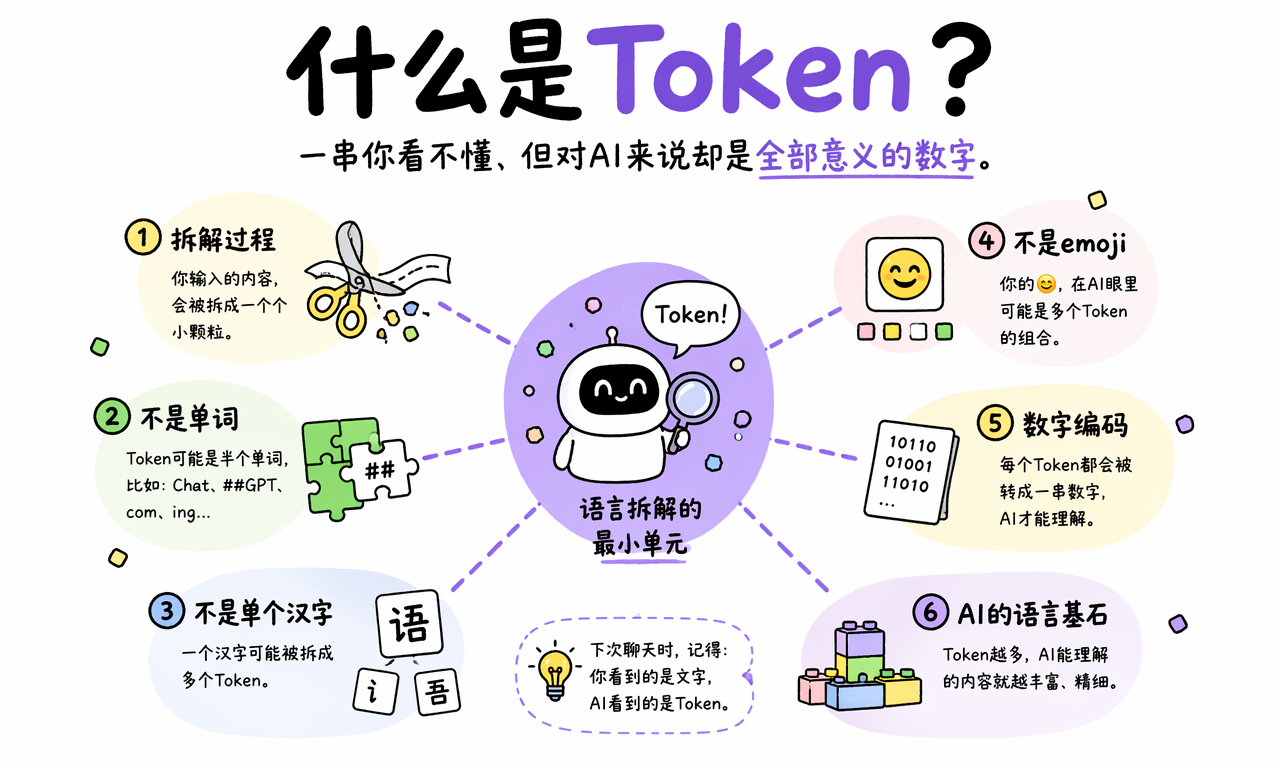
更直接地说,Token 是人类语言和机器数学之间的翻译单元。你在对话框里看到的是文字,模型真正接收和计算的是一串 Token ID。
你每次和 ChatGPT 或其他 AI 助手聊天,背后都有一个隐形工序:输入内容会先被拆解成小颗粒,再映射成数字。模型不是直接“看懂”文字,而是在数字序列上计算下一个最可能出现的 Token。
这篇文章用三个问题串起 Token 的底层逻辑:
- Token 如何把文字变成数字?
- 为什么 AI 服务按 Token 收费?
- 为什么上下文窗口决定了模型的“记忆力天花板”?
结论先说:Token 是翻译官、计量单位,也是一面墙。它既让 AI 能读懂输入,也决定了调用成本和模型当下能记住多少内容。
Token 为什么重要
Token 重要,是因为它同时影响 AI 的理解方式、使用成本和可处理信息量。只要你在使用大语言模型、AI 搜索、代码助手、文档总结或多模态模型,就会间接使用 Token。
对普通用户来说,Token 决定一次对话能放进多少上下文。对开发者来说,Token 决定 API 调用成本、响应速度和长文档处理方案。对产品设计者来说,Token 决定聊天记录、知识库检索、文件上传和输出长度应该如何控制。
Token 带来的实际变化可以概括为三点:
- 成本可计量:输入和输出都能按 Token 统计,方便估算 API 费用。
- 上下文可管理:长对话和长文档可以按 Token 预算拆分、摘要或检索。
- 多模态可统一:文字、图像、声音和代码都可以被编码成模型可计算的表示。
因此,理解 Token 不是为了记住一个术语,而是为了更准确地设计 AI 工作流、控制成本和解释模型为什么会忘记信息。
Tokenization 是怎么把文字变数字的
Tokenization 是把输入内容切成 Token 并转换成数字 ID 的过程。机器不认识字,它只认识数字,所以自然语言必须先经过这一步。
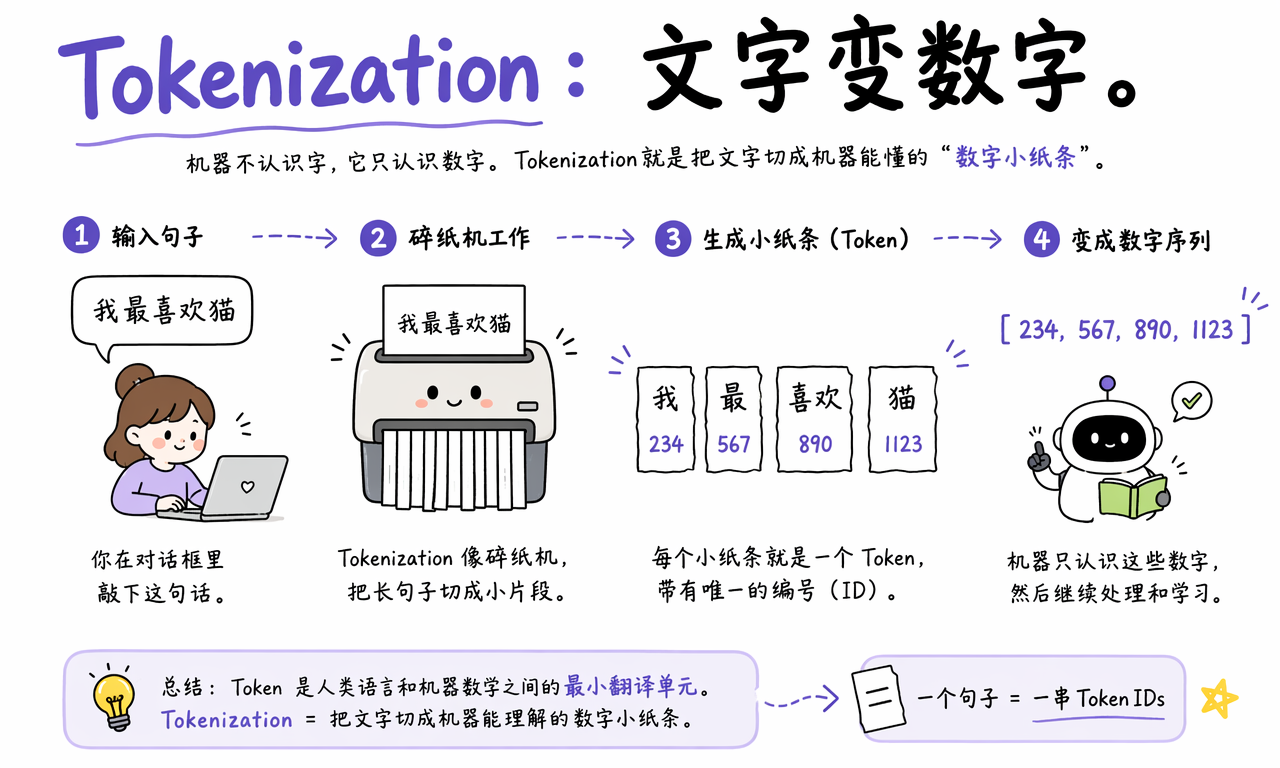
比如你输入“我最喜欢猫”,大模型看到的不是这几个方块字,而可能是一串类似这样的 ID:
[234, 567, 890, 1123]
这个例子里的数字只是示意,不同模型、不同 tokenizer 会得到不同结果。重点不是具体编号,而是过程:一句话会先被拆成 Token,再被查表转换成模型可以处理的数字序列。
你可以把 Tokenization 想象成碎纸机。你把一句话扔进去,它切成一张张带编号的小纸条;模型拿到的不是原句,而是这些编号纸条。
Tokenization 的作用是让语言进入数学空间。没有 Token,模型就无法用矩阵计算、概率分布和神经网络去处理人类表达。
中文 Token 为什么不是一个字也不是一个词
中文 Token 的切分方式不固定。同一个词在不同模型里,可能被切成一个 Token,也可能被切成多个 Token。
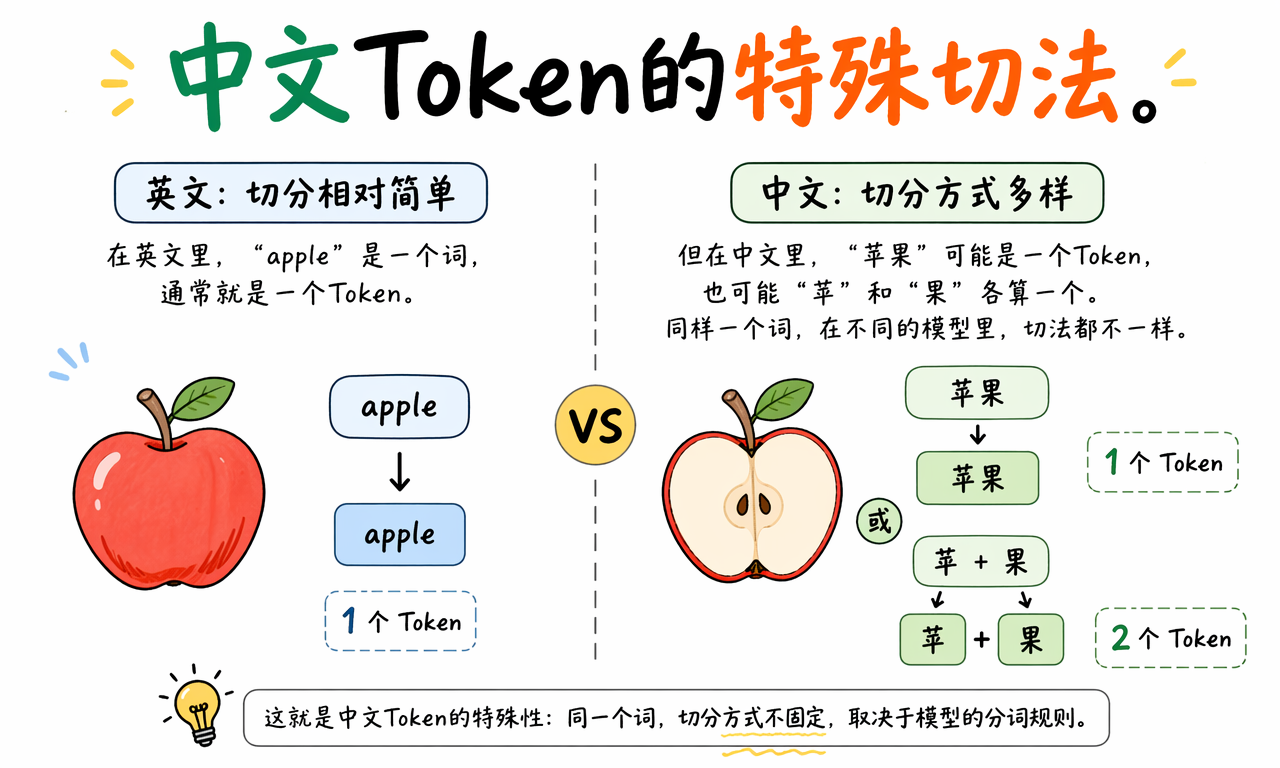
英文里,“apple”常常可以作为一个 Token。中文里,“苹果”可能是一个 Token,也可能被拆成“苹”和“果”两个 Token。emoji、标点、空格、代码缩进也都可能被单独处理,或者和相邻内容组合处理。
这说明 Token 不是词语。词语是语言学概念,Token 是模型工程概念。Token 的边界由模型的 tokenizer、词表和训练数据统计规律决定。
一个简单对比:
| 对象 | 人类怎么看 | 模型可能怎么切 | 关键点 |
|---|---|---|---|
| apple | 一个英文单词 | 一个 Token | 高频英文词常被整体保留 |
| 苹果 | 一个中文词 | 一个或两个 Token | 中文切分取决于 tokenizer |
| 😊 | 一个 emoji | 一个或多个 Token | 屏幕字符不等于 Token 数 |
function() | 一段代码 | 关键字、符号、括号分别切 | 代码也会被 token 化 |
所以,估算 Token 数不能只按“字数”或“词数”粗暴换算。精确结果要看具体模型使用的 tokenizer。
为什么不能一个汉字算一个 Token
如果每个汉字都固定算一个 Token,很多句子会变得很长,计算成本也会升高。大模型会做一种“经济账”:尽量用更短的 Token 序列表达更多信息。
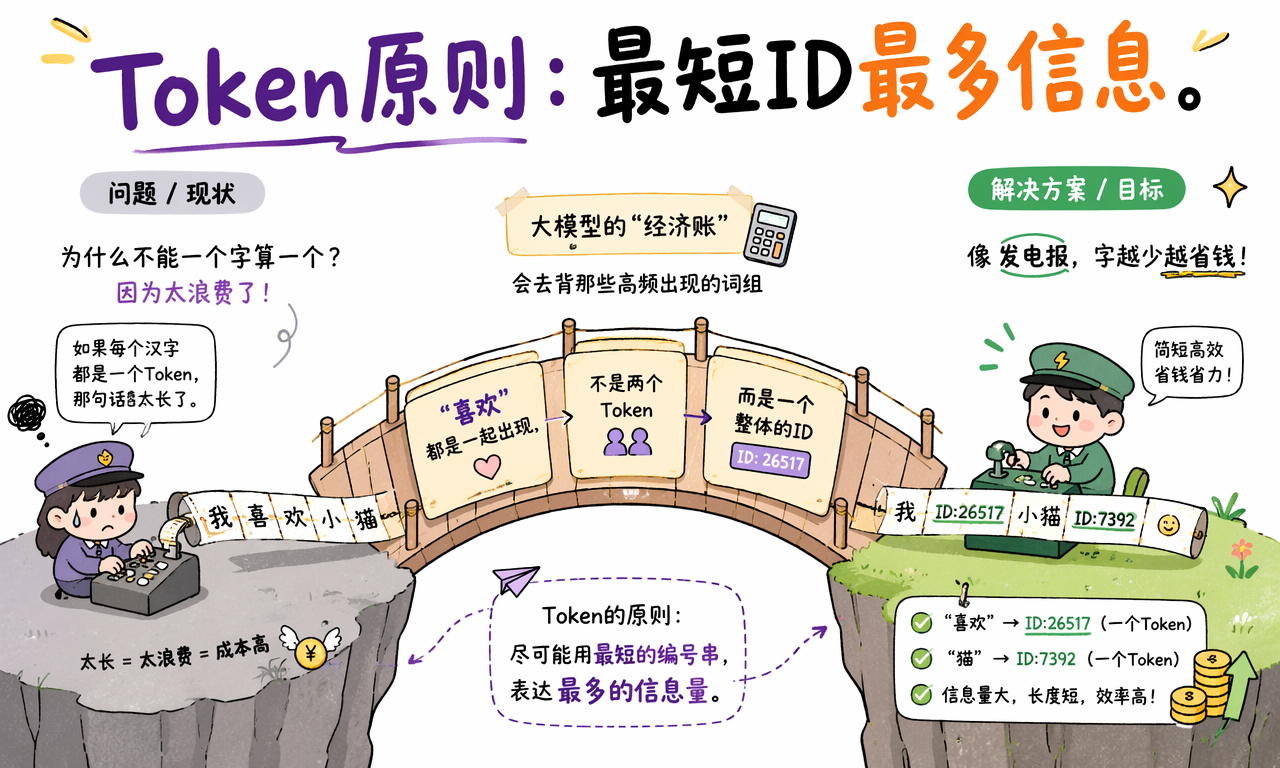
高频词组经常会被词表整体收录。比如“喜欢”经常一起出现,它就可能不是“喜”和“欢”两个 Token,而是一个整体 ID。“猫”很常用,也可能独立成为一个 Token。
这很像发电报:字越少,传输越省。Tokenization 的目标不是符合人类字典,而是在统计上尽量高效。
Token 的核心原则可以概括为三点:
- 高频片段优先保留:常见词、常见符号组合更容易成为独立 Token。
- 低频片段可以拆开:少见词、专有名词、生僻字可能被拆成更小片段。
- 总长度尽量压缩:模型希望用更少的 Token 表达足够多的信息。
因此,Token 是语言压缩和模型计算之间的折中方案。它既要让信息不丢失,也要让序列不要太长。
Token 和词语的本质区别是什么
Token ID 本身没有人类语言里的固定意义。它只是词表里的一个编号,真正的意义来自模型训练后学到的统计关系。
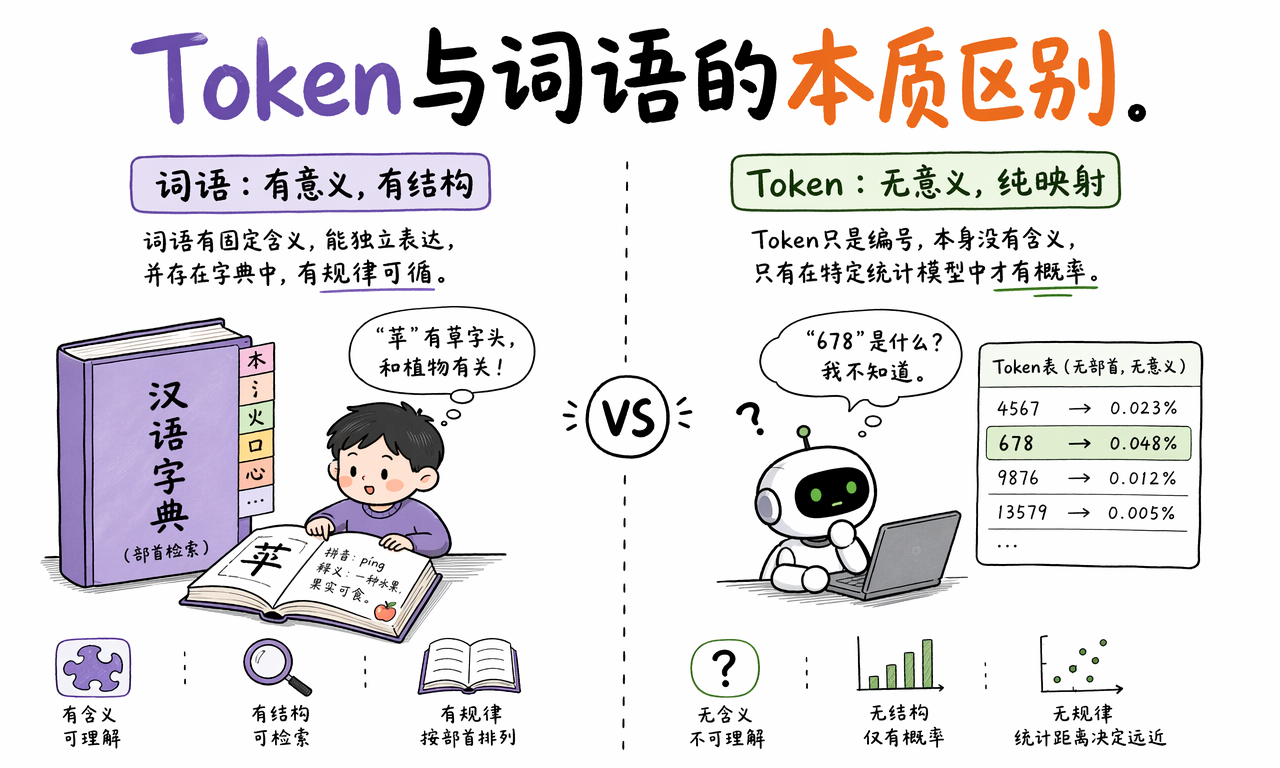
“苹”这个汉字单独拿出来,有字形、读音和含义。但如果你只拿到 Token 编号 678,你并不知道它代表什么。编号 4567 和编号 9876 之间,也没有偏旁部首关系。
人类字典按部首、拼音、词义组织。Token 词表更像一张映射表:某段文本片段对应某个 ID。模型再通过海量训练,学习这些 Token 在上下文里怎样相互靠近、怎样互相预测。
这就是 Token 和词语的关键区别:
| 维度 | 词语 | Token |
|---|---|---|
| 本质 | 语言单位 | 计算单位 |
| 是否有固定语义 | 通常有 | ID 本身没有 |
| 组织方式 | 字典、语法、语义 | 词表、编号、统计关系 |
| 是否跨模型一致 | 基本一致 | 不同模型可能不同 |
| 主要用途 | 人类理解和表达 | 模型计算和生成 |
准确地说,不是 Token 天生有意义,而是模型通过训练学会了在 Token 之间建立概率关系。
为什么说万物皆可 Token
Token 不只属于文字。只要能被切成片段并映射成数字,就可以进入模型的计算空间。
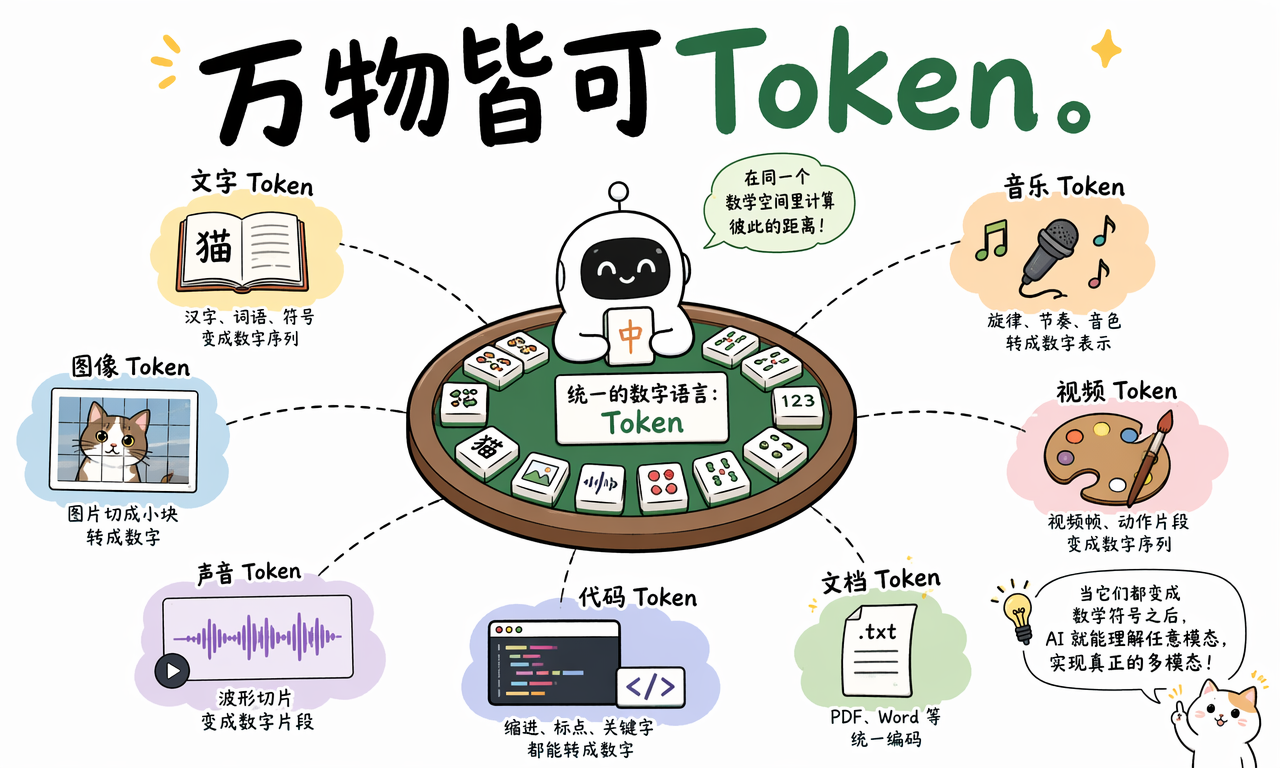
这也是多模态模型能够处理文字、图片、声音、视频和代码的原因之一。不同类型的信息会先被编码成模型可处理的数字表示,再在同一个或相近的数学空间里参与计算。
常见例子包括:
- 文字 Token:汉字、词语、符号、空格、标点被转成数字序列。
- 图像 Token:图片被切成小块或特征片段,再转成向量表示。
- 声音 Token:语音波形、音素、节奏等被编码成数字片段。
- 代码 Token:关键字、变量名、缩进、括号和运算符被拆解处理。
- 文档 Token:PDF、Word、网页内容通常会先抽取文本或结构,再进入模型。
看起来是 AI “看懂了图”或“听懂了声音”,底层更准确的说法是:这些信息被翻译成模型可计算的 Token 或向量表示,之后再和文字一起参与推理。
为什么大模型按 Token 收费
大模型按 Token 收费,是因为每个输入 Token 和输出 Token 都会消耗计算资源。Token 越多,模型需要处理的序列越长,推理成本通常越高。
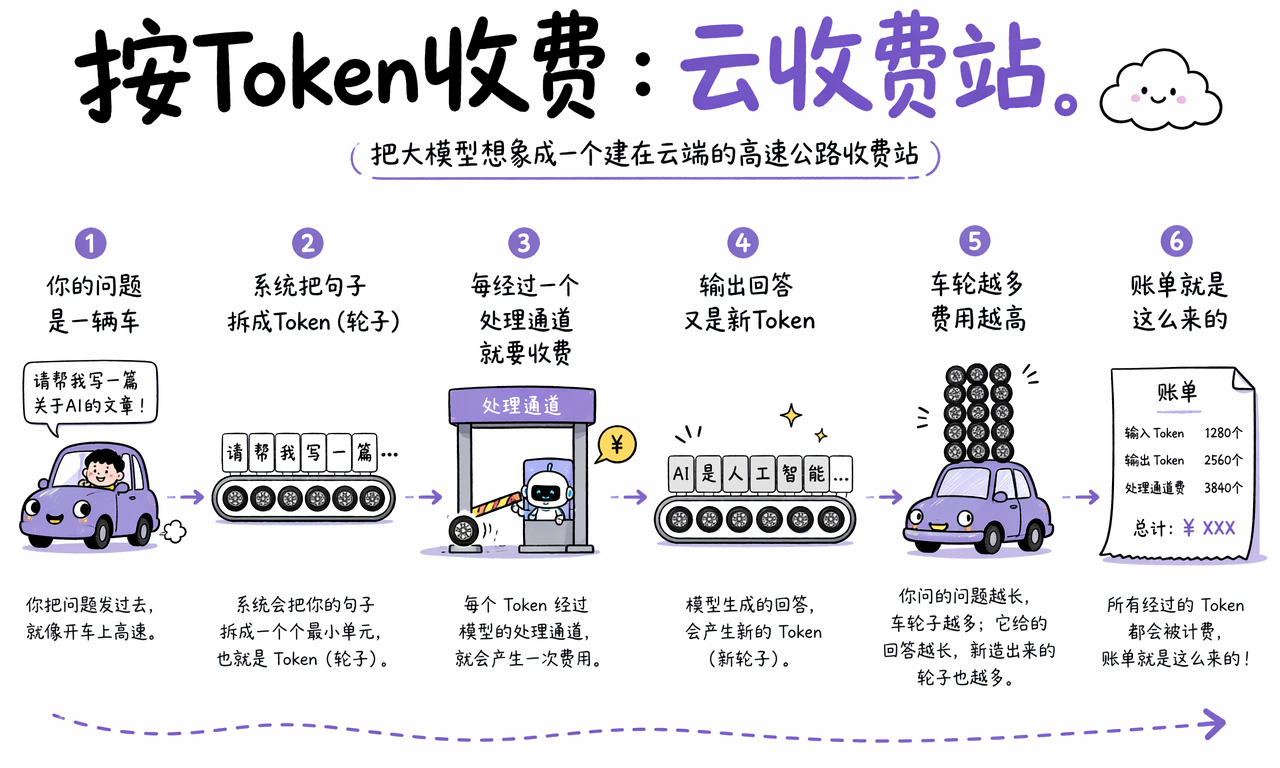
你可以把大模型想象成建在云端的高速公路收费站。你的问题是一辆车,Token 是车轮。
收费站不是简单按“来了一辆车”收费,而是按经过处理通道的轮子数量收费。你的输入会被拆成一串 Token,模型生成回答时又会一个 Token 一个 Token 地吐出新内容。
账单通常由两部分组成:
- 输入 Token:你的问题、系统提示词、历史对话、上传文档等内容。
- 输出 Token:模型生成的回答、代码、摘要、翻译或结构化结果。
有些 AI 平台还会区分输入和输出单价,或者对缓存内容、长上下文、复杂推理采用不同计费规则。但底层逻辑相同:模型处理的 Token 越多,成本越高。
所以,长提示词、长文件、长回答都会增加费用。优化 AI 成本,本质上经常是在优化 Token 使用量。
上下文窗口为什么决定模型记忆力
上下文窗口是模型一次能读取和处理的最大 Token 数。它限制的是 Token 数量,不是中文字数、英文词数或文件页数。
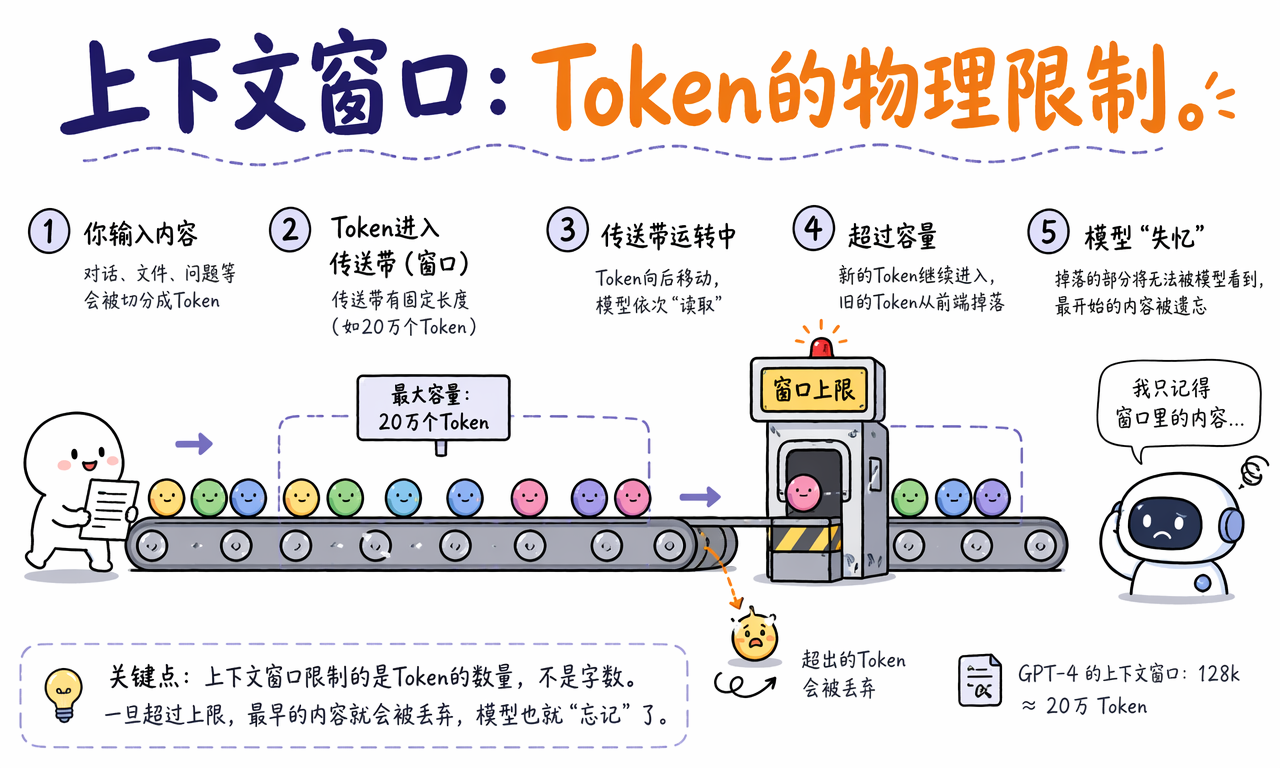
窗口像一条传送带。你输入的问题、历史对话、系统提示词、文档内容都会被放到这条传送带上。传送带长度有限,最多只能容纳一定数量的 Token。
如果一个模型标称支持 128k 上下文,意思是它最多处理约 12.8 万个 Token 级别的上下文,而不是 12.8 万个汉字,也不是一本书的全部内容都能无损记住。
一旦输入内容超过窗口容量,系统通常需要截断、压缩、检索或摘要。最前面的 Token 可能被丢掉,模型也就无法再直接看到最早的对话内容。这就是用户感受到的“AI 失忆”。
上下文窗口带来三个实际影响:
- 对话越长,早期信息越容易被挤出窗口。
- 文件越大,越需要摘要、分段或检索增强。
- Prompt 越冗长,留给模型回答和记住关键信息的空间越少。
因此,模型的短期记忆天花板不按“聊了多少轮”计算,而按“窗口里还剩多少 Token”计算。
Token 的三个身份是什么
理解 Token 的三个身份,就理解了生成式 AI 的一条主线:它先把世界翻译成数字,再按数字计费,最后又被数字窗口限制记忆。
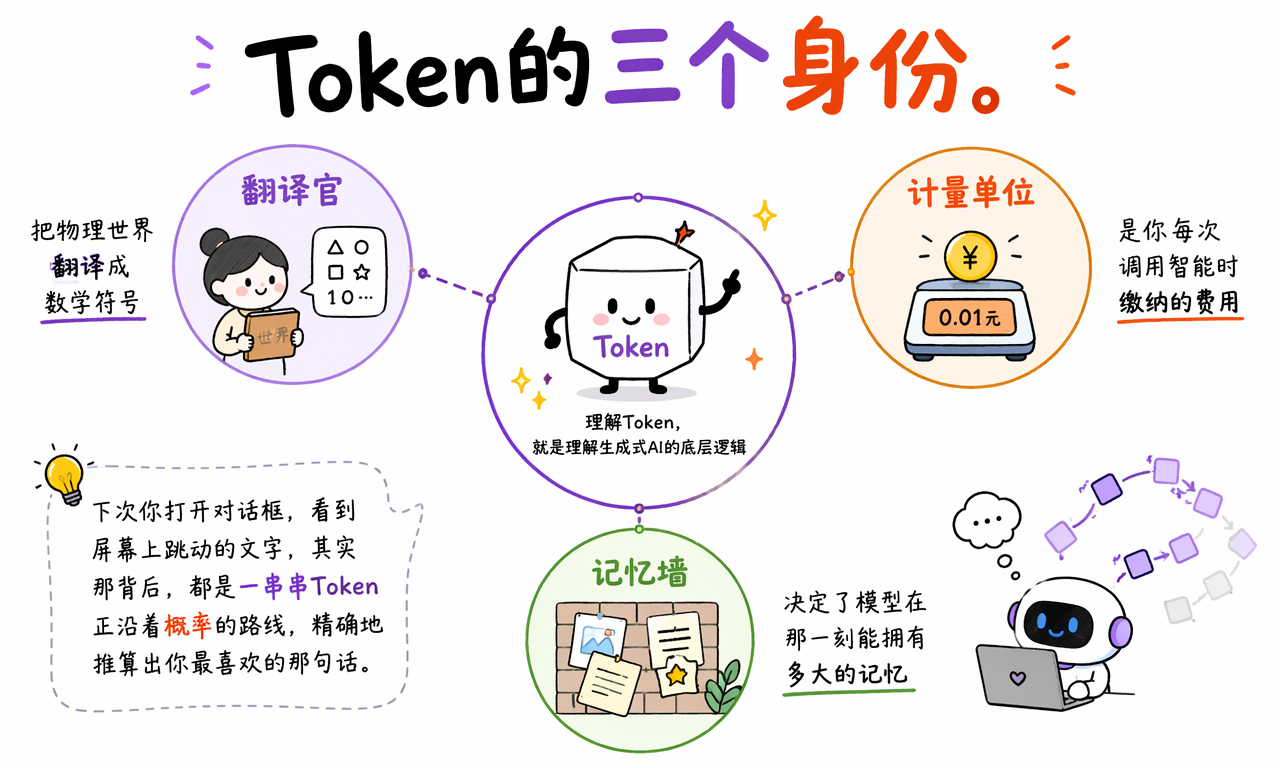
Token 的三个身份分别是:
- 翻译官:把文字、代码、图像、声音等内容翻译成模型可计算的数字表示。
- 计量单位:衡量输入和输出长度,决定 AI 调用成本的一部分。
- 记忆墙:构成上下文窗口,限制模型当下能读取的信息范围。
这三个身份解释了很多看似分散的 AI 现象:为什么同一句话在不同模型里长度不同,为什么长文档处理更贵,为什么聊久了模型会忘记前面的内容。
Token 在实际 AI 工作流里怎么用
在实际 AI 工作流中,Token 通常用来做预算、拆分和压缩。用户不一定直接看到 Token,但产品和开发者会围绕 Token 设计输入、检索和输出策略。
常见场景如下:
| 场景 | Token 影响什么 | 更好的做法 |
|---|---|---|
| 长文档总结 | 文件内容可能超过上下文窗口 | 先分段摘要,再合并总结 |
| 客服机器人 | 历史对话越长,窗口越容易被占满 | 保留关键状态,压缩旧对话 |
| 代码助手 | 代码、注释、报错和依赖文件都会占 Token | 只提供相关文件和错误上下文 |
| AI 搜索/RAG | 检索结果要塞进模型上下文 | 控制召回片段数量和长度 |
| 批量生成内容 | 输出越长,费用越高 | 规定结构、长度和停止条件 |
这类工作流的共同原则是:把最相关的信息留在上下文窗口里,把无关或重复信息提前删除、摘要或放到外部存储中。
使用 Token 时有哪些常见误区
Token 很基础,但也最容易被误解。下面这些误区会直接影响成本、效果和上下文设计。
| 误区 | 更准确的理解 | 实际影响 |
|---|---|---|
| Token 等于汉字 | 中文词组可能合并,也可能拆开 | 字数不能精确推算费用 |
| Token 等于单词 | 英文单词也可能被拆成词根或片段 | 生僻词、代码、URL 可能更耗 Token |
| 128k 等于 128k 字 | 上下文窗口按 Token 计 | 长文件可能远超窗口 |
| 模型会永久记住对话 | 模型只能直接看到当前窗口内内容 | 长对话需要摘要或外部记忆 |
| 图片不是 Token | 多模态模型会把图片编码成可计算片段 | 图片输入也会消耗资源 |
最实用的建议是:重要任务不要只看字数,要看 Token 预算。长文档、长 Prompt 和长回答都要为上下文窗口和费用留余量。
常见问题
Token 是什么?
Token 是大模型处理信息的最小计算单位。它可以是一个词、一个汉字、一个标点、一个英文单词片段、一个 emoji 的一部分,或者其他被模型编码后的信息片段。
Tokenization 是什么?
Tokenization 是把文本或其他输入切分成 Token,并映射成数字 ID 的过程。模型真正计算的是这些 ID 或它们对应的向量表示。
为什么中文 Token 数不好估算?
因为中文没有天然空格分词,而且不同 tokenizer 会使用不同词表和切分规则。同一个“苹果”,在一个模型里可能是一个 Token,在另一个模型里可能是两个 Token。
AI 为什么按 Token 收费?
因为模型处理输入和生成输出都需要计算资源。输入 Token 越多,模型读得越长;输出 Token 越多,模型生成得越久,费用通常也越高。
上下文窗口和 Token 有什么关系?
上下文窗口的单位就是 Token。它决定模型一次能直接读取多少输入内容。超过窗口的部分需要被截断、压缩、摘要或通过检索方式重新找回来。
怎么减少 Token 成本?
减少 Token 成本的方法包括:缩短无关背景、复用结构化模板、让模型输出更明确的格式、先摘要再处理长文档、把大文件拆成分段任务。目标不是盲目变短,而是让每个 Token 都提供有效信息。
总结
Token 是一串你看不懂、但对 AI 来说承载全部计算意义的数字。它把人类表达拆成模型可以处理的片段,再让这些片段进入概率计算。
它是翻译官,把物理世界翻译成数学符号;它是计量单位,决定每次调用智能时要消耗多少资源;它也是一面墙,决定模型在那一刻能拥有多大的短期记忆。
下次你打开对话框,看到屏幕上跳动的文字,可以把它想象成另一层现实:背后是一串串 Token 正沿着概率路线,被模型逐个读取、计算和生成。